Machine Learning Yearning Book 정리
이 책은 Andrew Ng 교수님이 이북 형태로 공개한 책으로, 머신러닝 프로젝트를 구조화하고 개선하는 전략과 다양한 기법을 소개한다.
단순히 개념 소개라기보다는 머신러닝 모델을 만들면서, 접할 수 있는 다양한 케이스들에 대한 소개와 방법들을 예시와 함께 정리해놓은 책이다. 전체 58장으로 구성되어 있고, 무료로 다운로드 가능하기 때문에 실무적인 내용이나 트레이닝할 때 유의할 점 등을 어깨 너머로 배우기에는 좋은 책인 것 같다. 약 120페이지 정도이고, 주변의 번역해놓은 블로그도 많아서 영어 번역이 귀찮으신 분들은 참고하시면 좋을 것 같다.
책 정리는 모든 내용을 정리하기 보다는 내가 보면서 중복되는 내용 제거하고 도움될만한 것들 참고용으로 정리했다.
데이터 양과 모델 성능의 관계
- 전통적인 머신러닝 방법론은 데이터수가 늘어난다고 해도 performance가 이후에는 평탄해지지만, 신경망이 등장하면서는 더 깊은 모델일수록 데이양에 따라서 더 잘 동작하는 것이 보인다.
지표 선정
- 단순한 지표 선정의 중요성
- 좋은 모델을 선택하기 위해 평가지표를 사용하는데 결국 의사결정을 쉽게 하기 위해서는 단수화(하나의 지표)하는 것이 필요하다.(참고 지표는 많더라도, 의사결정을 위한 지표)
- human-level performance
- 보통 머신러닝 모델로 해결하려는 문제는 인간이 잘하고 있는 것들을 기계가 대체하려는 것들이 많다. 따라서 모델의 목표 성능을 Human-level로 선정하는 것이 좋다.
- 이렇게 했을 때 좋은 이유는 아래와 같다,
- 인간이 데이터 라벨링하기가 편하다.
- error analysis하는데 있어서 인간의 직관에 의존하기 좋다.
- 사람이 하는 퍼포먼스를 optimal error rate의 기준으로 삼을 수 있다,(기준을 잡기가 좋다.)
- 사람의 성능을 뛰어넘은 모델을 만드는 경우가 있더라도 여전히 인간은 잘 구분하고 기계는 구분하지 못하는 문제가 있다면 그런 것들을 학습시키면 더 좋은 성능의 모델을 만들 수 있다.
- 하지만 보통은 사람의 성능 > 모델의 성능인 경우가 더 성능 향상의 진행이 빠르다.
데이터셋의 구성
- 학습 당시에 배우는 데이터의 분포와 실제 적용 당시의 데이터의 분포가 달라지지 않는지 항상 유의해야한다. 우리가 만들 모델은 학습 데이터에 Fitting된 모델이 아닌 궁극적으로 사용하는 데이터의 성향을 반영한 데이터
- 이전의 머신러닝 단계에서는 100 ~ 10000개 정도의 데이터를 가지고 분석을 해왔고 그 기준으로 30% 정도를 테스트 데이터 비율로 가져왔지만, 수백만개의 데이터들을 활용하는 문제를 접하는 경우 절대적인 테스트 데이터 수는 많아도 실제로 비율은 줄어들게 된다.
- 개발 데이터를 가지고 있다는 것은 빠르게 모델을 이터레이션하면서 실험하기에 필수적이다.
- 개발 데이터에서 나온 결과가 테스트 데이터보다 더 좋게 나온다면 개발데이터에 overfitting된것으로 볼 수 있어서 개발 데이터를 바꿔보는 것도 도움이 될 수 있다.
Error Analysis
- 모델을 개선해나가는 과정에서 오류평가를 하는데 오류평가에서 어떤 것을 고치냐를 기준으로, 임팩트를 측정해볼 수 있다.(Ex. 고양이 감별 모델에서, 개를 잘못 판별하거나, blur 이미지를 해결 못하는 에러의 비중 보기) 오분류된 케이스를 100개 정도 뽑아보고 스프레드 시트 형태로 비중을 정리해보는게 더 우선순위를 평가한다고 한다.
- Error_rate 계산할 때, 잘못 레이블된 데이터로 야기된 에러율과 실제 알고리즘이 잘못 예측한 에러율을 비교해서 비중이 비슷하다면 오히려 레이블된 데이터를 개선하는게 우선순위가 올라갈 수 있다.
- 머신러닝 모델을 분석하다보면, 실제 에러 케이스들을 살펴보는 현상들이 있다. 하지만 모든 케이스를 보기보다는 이것또한 세트를 나누는 접근법을 추천한다.
- 유형
- eyeball dev dataset : 전체 Dev set의 10%, 실제 에러 케이스는 여기서만 본다.
- blackbox dev dataset : eyeball dev dataset을 제외한 데이터 셋, 실제 파라미터 파인튜닝이나 측정에 활용한다. black box dataset에서는 절대 에러케이스를 보지 않는다.
- 활용법
- eyeball dev dataset과 blackbox dev dataset의 성능을 비교해서 overfit 여부를 측정한다.
- 성능이 eyeball dev dataset > blackbox dev dataset이라면, Eyeball dev dataset의 error에 overfit되었다고 볼 수 있어서 이에 대한 대응을 해줘야한다.
- eyeball dev dataset을 다시 섞어준다.
- Tip
- 결국 데이터셋이 충분하지 않다면(약 100개 이상의 에러가 있는 Eyeball dev dataset이 이상적이다.) 전체 개발 데이터셋을 eyeball dev dataset으로 보는 것이 좋다.
- 유형
Bias - Variance TradeOff
- Task X에 대해, 오차율 5%달성이 목표라고 하자
- 알고리즘 A 목표와의 관계

*5%, 15%의 차이 정도면 학습 데이터를 늘리는 것만으로는 해결이 어렵고 알고리즘으로 해결해야 한다.
- 편향과 분산 분류
- 너무 모델을 크게 만들수록 과적합을 만들 수 있다는 tradeoff가 있기 때문에 Regularization나 dropout을 하면 성능이 안정적으로 증가시킬 수 있다.
- Training set에 대해서도 error analysis를 하는 것이 high bias를 낮출 수 있다. 100개 정도 샘플링해서 어떤 유형의 문제가 있는지 사람이 들어도 해결할만한 문제인지를 확인하는 것이 좋다.
Learning Curve
- training data 갯수에 따른 error 그래프로 시간이 지남에 따라 error는 수렴할 것이다. 이를 보면서 우리가 낮추고 싶은 목표를 함께 그리면 시각적으로 비교해볼 수 있다.
- 트레이닝 셋이 커질수록 퍼포먼스가 떨어지는 이유는 트레이닝 데이터가 많아지면 모든 데이터를 다 fit하기가 어려워지니까 당연히 퍼포먼스가 떨어질 수밖에 없음. 즉, 2개 데이터를 다 맞추는 건 쉽지만 200개 데이터를 맞추는건 어려운것과 같은 이치이다.
- 유의할 점
- 소규모 데이터셋 실험시, 너무 좋은 케이스나 너무 나쁜 케이스가 그려질 가능성이 있다.
→ 1개의 샘플만 뽑지 말고 여러개 뽑아서 평균내거나 해서 그리는 방법 - 분류 모델인 경우 너무 한쪽으로 class가 집중된 경우(데이터셋의 분포가 서로 다른 문제)
→ 층화추출처럼 비율을 맞춰서 구분해본다. - 1000 → 10,000개로 1000개씩 늘려가면서 데이터 학습시키는건 학습비용이 과도하다.
→ 1000, 2000,4000,6000,10000으로 늘려간다.
- 소규모 데이터셋 실험시, 너무 좋은 케이스나 너무 나쁜 케이스가 그려질 가능성이 있다.
데이터셋 분포
- 학문적으로는 train/dev/test dataset이 동일한 데이터 분포를 가지고 있다는 전제이지만 실제로는 그렇지 않은 경우들이 많다.
- 최근에는 Transfer Learning이라는 것들도 있지만 이는 모델이 정말 큰 경우이고 특정 테스크 한정된 작은 모델의 경우에는 어렵다고 볼 수 있을 것 같다.
- 이전까지는 실제로 앱에서의 이미지와 인터넷에서 다운로드 받은 이미지가 있는 경우 앱에서 유저가 기여한 이미지만 사용하도록 권장했다.
- 하지만 DNN의 크기가 발달하면서 굳이 그렇지 않아도 된다는 의견이 등장했다.
- 결국은 “고양이”를 판별하는 공통적인 특성을 학습하기 때문에 분포가 다르더라도 모델이 충분히 크면 판별하는 알고리즘을 강화하는데 도움을 줄 것이다.
- 인간의 뇌도 동일하게 한정된 공간이 있기 때문에 데이터가 많지만 capacity가 부족한 경우에는 성능이 떨어질 수도 있다.
- 하지만 DNN의 크기가 발달하면서 굳이 그렇지 않아도 된다는 의견이 등장했다.
- 실제로 어떻게 적용할 수 있을까?
- computational cost가 무한하다면, 이 두가지 데이터셋을 다 충족시킬만큼 충분히 큰 모델을 학습시키면 된다.
- 하지만 효율적으로 접근하려고 한다면 아래와 같이 목적함수를 최소화하면 이를 충족할 수 있다.(Weighting)
- Loss Function(Mobile Image) + b * Loss Function(Internet Image)
- 모델의 성능 측정을 위해 데이터셋을 4가지로 나누는 방법이 있다.
- Training Set : 알고리즘이 학습해야하는 데이터로 꼭 우리가 실제 고민해야할 데이터와 같은 분포에서 나올 필요는 없다.
→ 1) Training Error - Training Dev Set : 트레이닝 셋과 같은 분포에서 나온 것으로 트레이닝 셋보다는 보통 크기가 작다.
→ 2) 트레이닝 자체를 잘했는지를 측정하기 위한 용도 - Dev Set : 테스트 셋과 동일한 분포로 나와야하고 우리가 궁극적으로 해결하려는 데이터의 분포를 반영해야한다.
→ 3) 실제 성능 - Test Set : dev set과 같은 분포에서 나와야한다.
- Training Set : 알고리즘이 학습해야하는 데이터로 꼭 우리가 실제 고민해야할 데이터와 같은 분포에서 나올 필요는 없다.
- 측정 방식
- 1과 2의 측정 : 학습이 잘되었는가
- 2와 3의 측정 : data 분포 문제가 있는지(Data Mismatch)
- 각 케이스별 정의
- Data mismatch : 테스트 데이터셋과 트레이닝 데브셋과의 에러가 차이가 많이 날 경우
- Variance : 일반적으로 트레이닝 셋과 데브셋과의 데이터 분포 차이가 나는 경우
- Avoidable Bias : 목표 에러와 트레이닝 에러의 차이가 큰 경우
데이터 증강(합성)
- 예를 들어, 우리가 사람들의 목소리를 인식하는 모델을 만든다고 하자.
- error analysis를 해보니 차에서 대화하는 케이스에 대한 error가 높은 것을 확인했다. 하지만 우리가 학습해야하는 음성 데이터 1000시간 중 1시간만이 차(car) 소리가 들어간 데이터이다.
- 이 때 직접 그런 데이터를 모으는 방법이 있을 수 있겠지만, 차 데이터를 따로 모은다음에 기존 음성에 차 소리를 합쳐서 학습시키는 방법도 있다.
- 하지만 이 때 주의해야할 점도 바로 데이터 분포이다.
- 예를 들면 우리가 기존 음성에 합치는 차소리를 동일한 차소리를 더해버리면, 모델은 그 1시간짜리 차소리에 overfitting될 수밖에 없다.
- 배경에서 자동차를 인식하는 모델을 만드는 예시도 들어보면, 우리가 일반적인 배경에 자동차를 붙여넣어서 데이터를 인위적으로 합성하면 많은 데이터를 만들어낼 수 있다.
- 하지만, 우리가 붙여넣는 자동차가 20개 정도의 차종이면 모델은 20개 차종에 overfitting될 수 있다.
- 해결책으로는 세계의 자동차 분포를 고려해서 데이터 분포를 맞추는 방법이 필요하다.
Optimization Verification Test(최적화 검증 문제)
- 우리가 만드려는 모델 중에서는 Speech to Text 모델이라고 하자.
- 음성 input X가 들어갔을 때 모델이 뱉어낸 text를 S라고 한다면, 그 모델이 가진 performance를 우리는 score(s)라고 할 수 있다.
- 우리의 모델은 결국 우리가 정의한 score(X,S)에 대해서 그 스코어가 가장 큰 S를 찾는 것이라고 볼 수 있다.
- 하지만 스코어가 가장 커지는 S를 찾는 문제는 단번에 찾을 수 있는 것은 아니고 일종의 답을 찾는 search 알고리즘이 필요하다.
- 모델의 성능이 잘 안나올 때 우리는 두가지 문제를 원인으로 추정할 수 있는데 이 둘을 구분하는 방법이 최적화 검증 문제다.
- 문제1) Search algorithm problem : score를 최대화하는 S를 찾는 최적화 알고리즘의 문제
- 문제2) Objective problem : 인간이 score를 설계하기 때문에 예상치 못한 예외케이스가 발생할 수 있고 우리가 의도한대로 score가 정의되지 않을 수 있다. 즉, Objective scoring function 자체가 문제일 수 있다.
- 이걸 어떻게 테스트할 수 있을까?
- 실제 우리가 labeling한 정답 데이터의 스코어를 score(y)라고 하고, 모델이 내놓은 답의 스코어를 score(output)이라고 하자
- score(y) > score(output)인 경우 : 최적화 문제이다.
- score(y) ≤ score(output)인 경우 : 애초에 실제 정답보다 스코어가 높이 나오면 안되기 때문에 Objective function의 문제다.
- 이를 강화학습에 적용한 예제를 살펴보자
- 우리가 헬리콥터를 자동으로 운전하는 모델을 만든다고 하자.
- 이 때 각각의 경로를 만드는 알고리즘이 있고 이 비행이 좋은지를 측정하는 score function이 있다고 하자. 강화학습에서는 이를 보상함수라고 한다.
- 인간이 헬기를 운전하는 경로를 최적의 경로라고 하고, 실제로 모델이 운전하는 경로의 스코어를 비교해서 Optimization Verification Test를 실행할 수 있다.
- 이를 통해서 우리는 알고리즘을 개선하는게 좋을지 보상함수를 개선하는게 좋을지 알 수 있게 된다.
End to End learning

- 우리가 감정분석 모델을 만든다고 하자. 이 때 우리는 두가지 Task를 연속적으로 수행하는 파이프라인을 만들어야 한다.
- Parser : 문장을 품사 단위로 구분해주고, 각 품사를 지정해주는 동작을 하는 모델
- Sentiment Classifier : 기존 Task의 목적인 감정을 판단해주는 모델
- 이렇게 진행함으로써, 우리는 이전의 Parser에서 나온 품사 등을 input으로 활용해서 감정을 분류하는데 더 성능을 높일 수 있다.
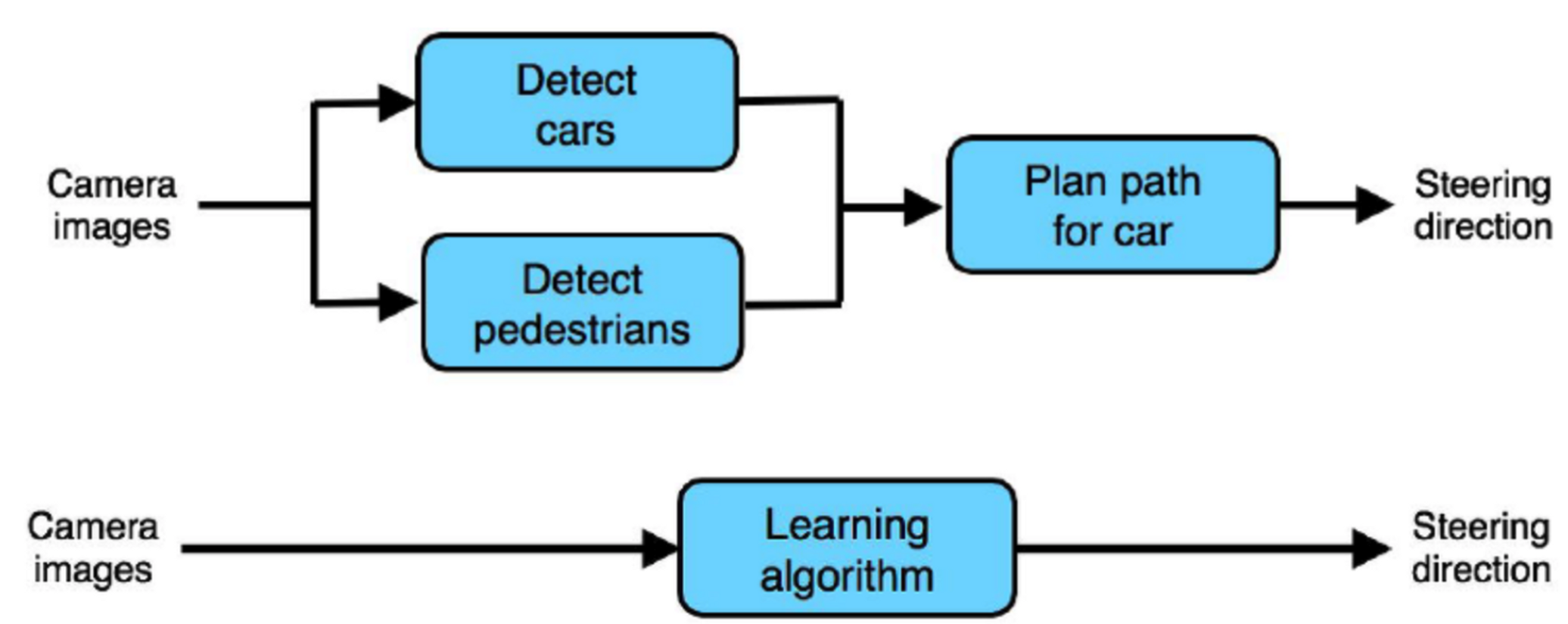
- 하지만 최근에는 처음부터 끝까지 다 하나의 learning algorithm이 다 알아서 학습하고 분류할 수 있게 하는 모델로 구현하는 경우가 있다.
- 파이프라인 VS End to End Learning 중에 우리는 어떠한 케이스에 각 방법을 선택해야할까?
- 일반적으로 라벨링된 데이터가 많다면, 굳이 파이프라인을 나눠서 모델을 만들어갈 필요가 없다.
- 하지만 데이터가 적고, 알고리즘 설계에 인간의 직관이 많이 들어가야하는 경우에는 파이프라인을 설계하는 방식을 선호한다.
파이프라인 요소 선택 기준 1) 데이터 가용성
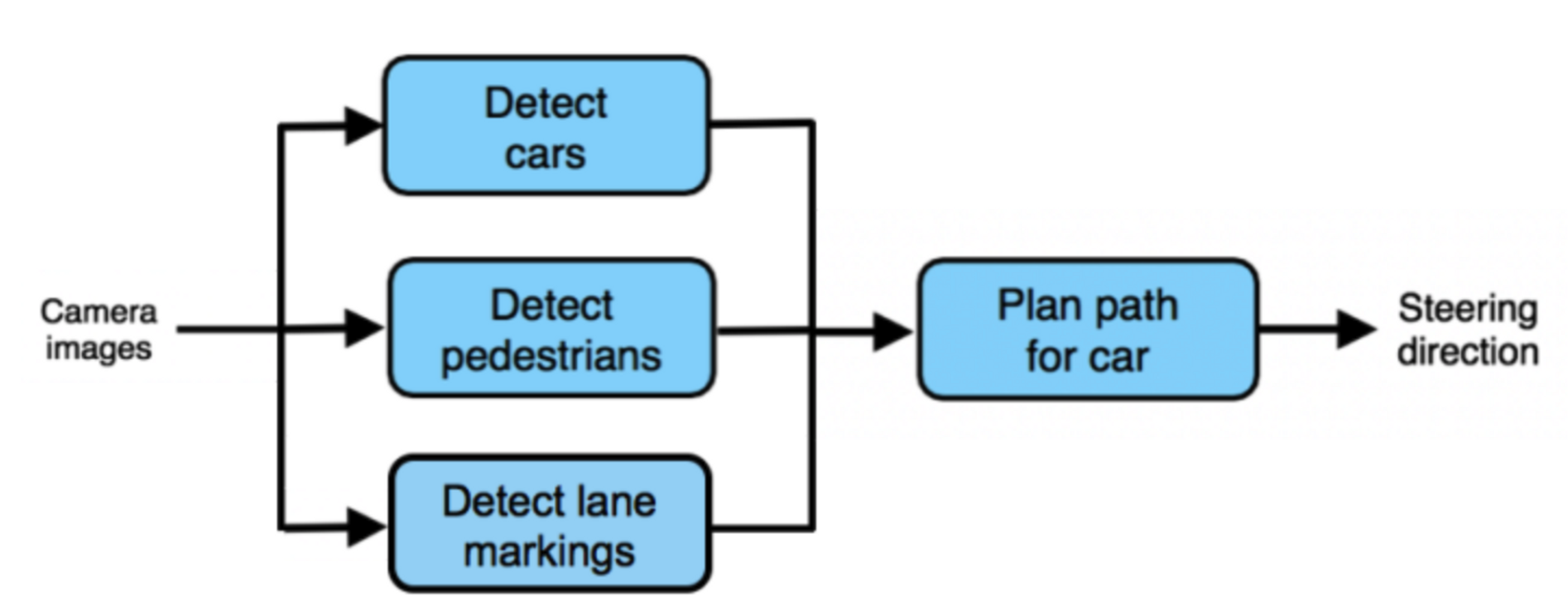
- 자율주행 모델을 만든다고 하자. 위의 그림 1은 카메라 이미지 → 차/보행자를 인식 → 그에 따라 운전방향을 설정하는 모델인 반면, 그림 2는 카메라 이미지를 통해서 바로 운전 방향을 설정하는 모델이다.
- 데이터를 확보하는 관점에서 그림1의 방식은 사진 라벨링, 보행자 라벨링 등은 일부 비용을 쓰긴 하지만 라벨링하는 방법을 교육시키는데 있어서 좀 더 편리하지만 그림 2의 방식은 이미지, 회전 방향 쌍으로 구성된 데이터군이 많이 필요할 것이고 실제로 특별한 장치가 부착된 차도 필요할 것이다.(여담이지만 테슬라는 가능할 것 같다..)
파이프라인 요소 선택 기준 2)Task 복잡성

이미지에 대해서 아래 5가지 테스크를 수행하는 머신러닝 모델들은 구현 용이성에 따라 쉬운순으로 번호를 나열했다.
- 해당 이미지가 과도하게 노출되었는지 여부를 구별하는 것
- 해당 이미지가 실내인지 야외인지 구별하는 것
- 해당 이미지가 고양이를 포함하고 있는 것인지를 구별하는 것
- 검정과 하얀 털로 구성된 고양이가 포함되어 있는지를 구별하는 것
- 해당 이미지가 siamese cat(고양이 종류 중 하나)을 포함하고 있는지를 구별하는 것
가장 복잡한 테스크인 5번을 예시로 들어보자.

단순히 0/1의 라벨을 사용해서 end-to-end 방식의 감지기를 학습시키는 것에 비해서, 아래의 고양이를 감지하는 분류기와 고양이 종 분류기로 구성된 요소들을 각각 학습시키기가 더 쉬워보이고 더 적은 데이터가 필요할 것이다.

즉 파이프라인의 각 요소로 어떤 것을 넣어야할지 결정할 때 각 요소들이 상대적으로 간단한 함수로 구성되어 한정된 데이터만 가지고 있어도 학습시킬 수 있는 요소로 파이프라인을 구성하는 것이 이상적이다.
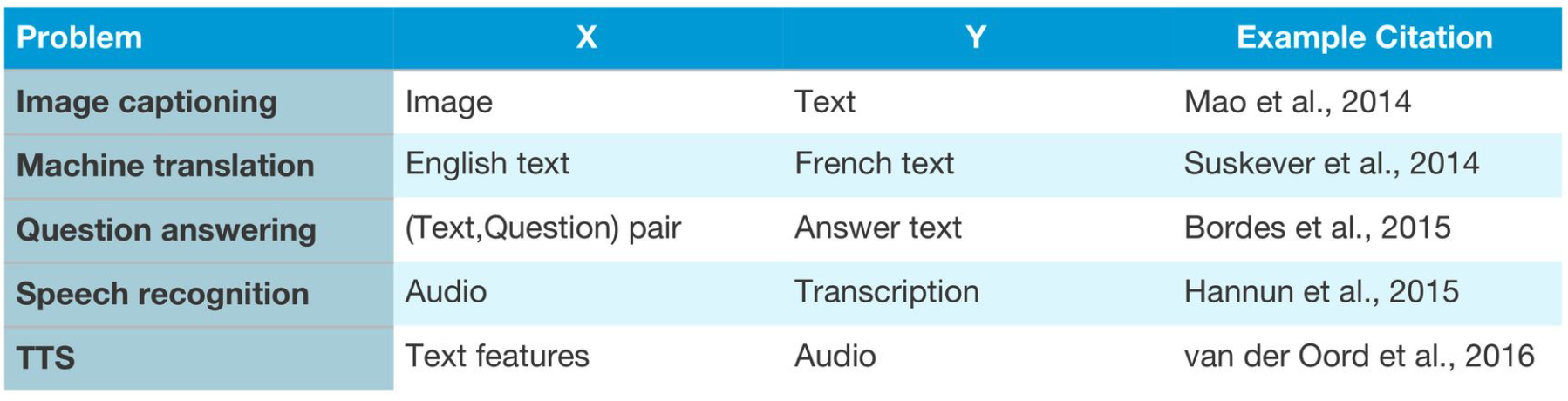
더 복잡한 output을 직접적으로 학습할 수 있는 방식(end-to-end learning)
이전까지의 딥러닝 모델들은 integer형태로 기다 아니다를 뱉어내는 모델들이었다.

하지만, 만일 우리가 아래의 그림에 대해서 단순 버스가 있다 없다를 0,1로 표현하는 모델이 아니라 그림에 대한 묘사를 output으로 내는 모델을 만들 수 있을까?

우리가 올바르게 x,y가 라벨링된 데이터 페어를 많이 가지고 있다면, 충분히 더 다양한 유형의 output을 뱉어낼 수 있는 모델을 만들어낼 수 있고, 실제 사례들을 아래에서 볼 수 있다.
파이프라인 요소별 에러 분석
- 각 요소별로 결과값들 중 error가 발생한 케이스들을 하나씩 뜯어보면서 어디에서 문제가 일어났는지 비중을 따져보는 것이 가장 1번째 작업이다.
- 예를 들어, 고양이 종 분류하는 모델에서 에러를 파악했을 때 고양이 자체를 인지 못하는 케이스가 몇 퍼센트이고, 고양이를 잘 인지했는데 종을 잘못 분류한 케이스가 몇 퍼센트인지 비교해보면서 모델의 우선순위를 따져본다.
- 하지만 error analysis를 하다보면 애매한 케이스가 발생할 수 있다.
- 예를 들어, 고양이를 감지하긴 했는데 눈, 귀만 감지한 경우라고 하자. 숙련된 인간이라면 종을 구분할 수 있기 때문에 이 때에는 어느 요소가 잘못되었는지 파악하기 위해서는 인위적으로 우리가 input을 명확하게 고양이를 감지하는 답을 줬을 때 어떻게 작동하는지 판단해보는 방법이 있다.
→ 이를 통해서 어떤 것이 잘못되었는지 확인해볼 수 있다.
- 예를 들어, 고양이를 감지하긴 했는데 눈, 귀만 감지한 경우라고 하자. 숙련된 인간이라면 종을 구분할 수 있기 때문에 이 때에는 어느 요소가 잘못되었는지 파악하기 위해서는 인위적으로 우리가 input을 명확하게 고양이를 감지하는 답을 줬을 때 어떻게 작동하는지 판단해보는 방법이 있다.
- 일반적인 방법론은 다음과 같이 정리해볼 수 있다.
- A의 출력이 “정답인” 출력이 되도록 수정해보고 이를 이용해서 B와 C에서 테스트해본다.
- 이후 과정이 잘 워킹하면 A에서 발생한 문제이기 때문에 A를 개선한다.
- 위 과정이 잘 출력되지 않는다면, B의 출력이 “정답인” 출력이 되도록 수정해본다.
- 위 두가지 과정이 정상적이지 않은 출력을 내보낸다면 오류는 C에서 발생한 것이다.
- A의 출력이 “정답인” 출력이 되도록 수정해보고 이를 이용해서 B와 C에서 테스트해본다.

4. 순서대로 있는 것이 아니라 병렬 구조로 되어 있는 경우에는 아래와 같이 정리해볼 수 있다.
- 병렬적인 경우가 있는데, 이 경우에도 우선 앞단 먼저 “정답인” 출력을 제공하고 나머지 변수를 통제해서 하나씩 테스트해보는 방식을 따르면 된다.
- 일종의 개발 테스트 시나리오와 비슷한 방식이라고 이해하면 된다.
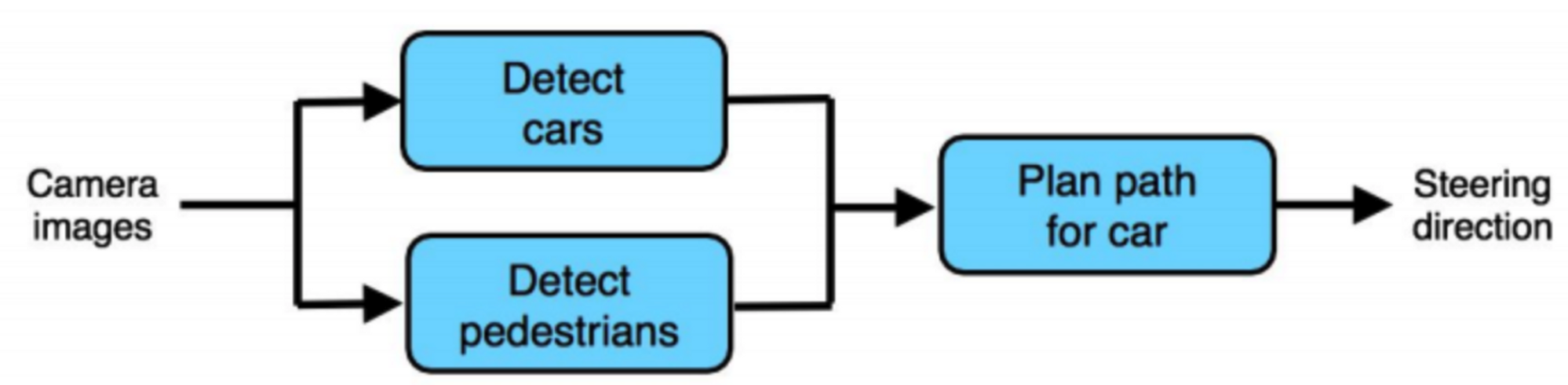
5. 별개의 방법으로 각각의 component들을 인간의 성능과 각각 비교해보고, 인간 성능 대비 가장 낮은 것부터 개선해나가는 것도 방법이 될 수 있다.
- 만일 각 요소가 인간 성능 지표와 근사하지만 전체 성능이 인간 성능 지표에 도달하지 않은 경우에는 파이프라인 자체 구성에 결함이 있고, 재 설계될 필요성이 있다는 것을 의미한다.
- 이런 식으로 아예 파이프라인 자체를 추가하거나 순서를 바꾸는 방법이 그 예시다.