본 강의는 유튜브에 올라와 있는 "시각적 이해를 위한 머신러닝"이라는 서울대 데이터 사이언스 대학원(GSDS) 강의를 보고 정리한 글입니다. 대학원을 다니지 않고도 이렇게 좋은 강의를 들을 수 있어서 강의를 공유해주신 이준석 교수님께도 너무 감사합니다...
5~7강까지는 CNN, 신경망 훈련에 필요한 개념들에 대한 설명을 다루고 있고 이전에 동일한 교수님의 머신러닝과 딥러닝1이라는 강의 내용과 완전히 똑같아서, 새롭게 알게된 내용 & 메모해둘만한 내용 위주로만 정리했습니다!
원본 링크 : https://www.youtube.com/watch?v=mmk7dn2fIxE&list=PL0E_1UqNACXDTwuxUzCl5AeEjXBfWxCwc&index=6
5. Convolutional Neural Networks

앞서, 도메인별 context를 활용해서 Feature Extraction을 인간이 해왔는데 CNN은 이미지 연산이 가진 복잡성 & 이미지 인식을 돕기 위해 새로운 Neural Network 모델을 구성했다.
이미지를 판별하는데 세운 규칙
- Spatial Locality : 각각의 객체는 주변 픽셀만 보면 알 수 있다.
- Positional invariance : 같은 필터는 모든 위치에 적용이 된다. (사진은 찍는 구도가 다 다르기 때문에 위치와 관계 없이 눈은 눈이다.)
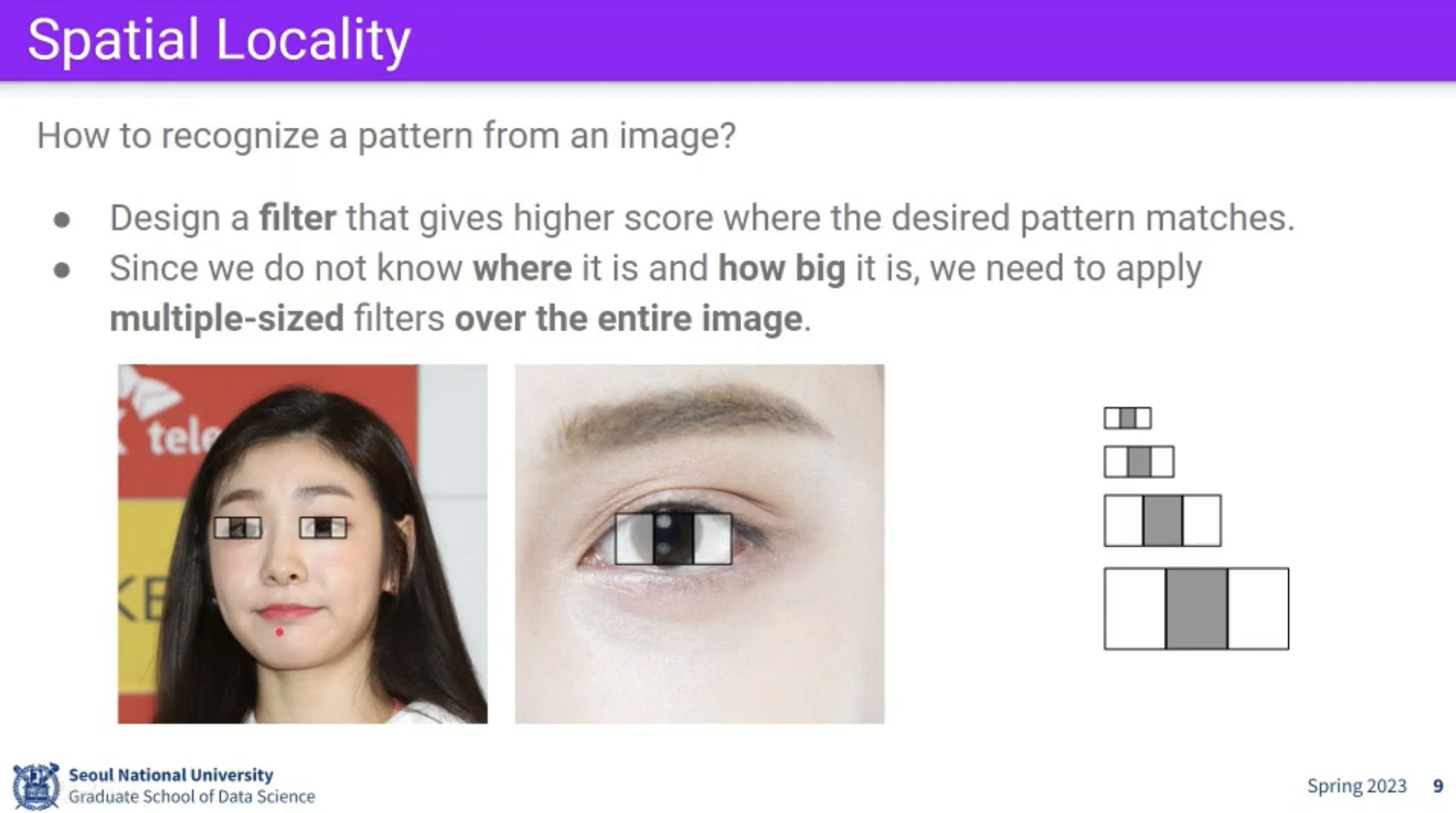
위 특성을 활용해 이미지 학습의 경우에는 linear하지 않고 일종의 필터를 추가한 layer를 convolution layer라고 하며 이를 활용해 만든 신경망을 CNN이라고 부른다.

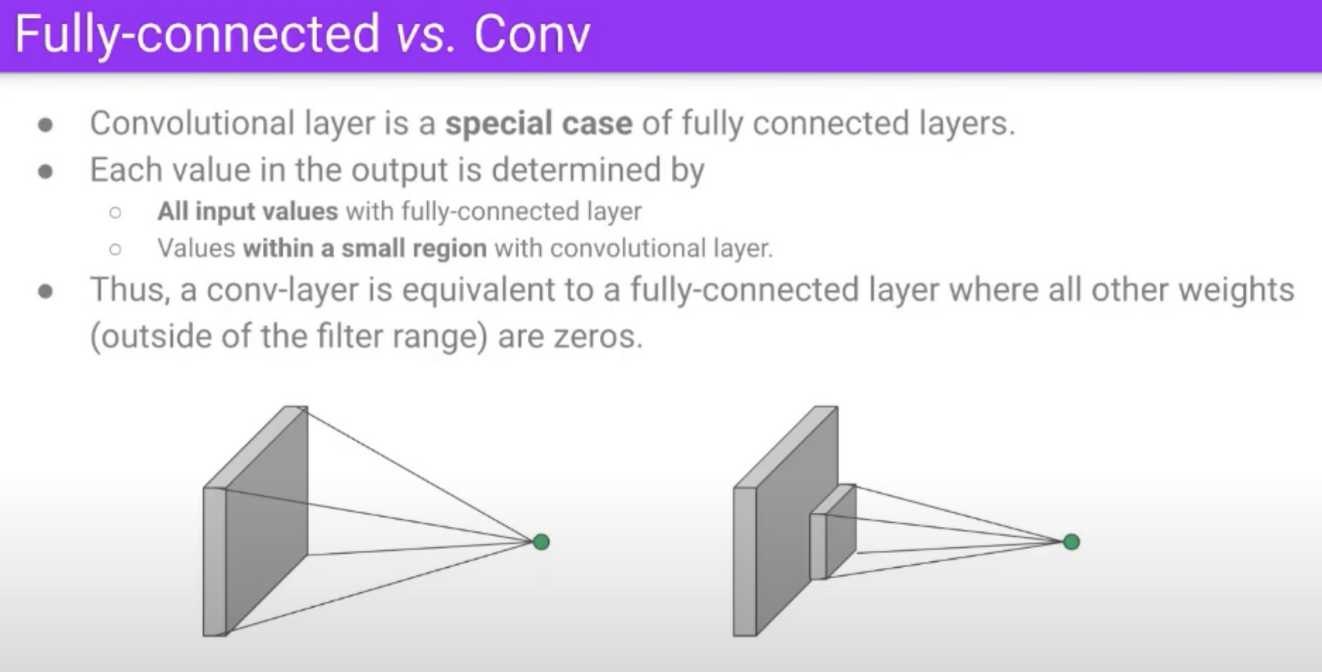
6. Training Neural Networks 1
활성화 함수가 가질 수 있는 문제
1. killing gradient
값이 너무 크거나 작은 경우 기울기가 0에 가까워지다보니, 그래디언트가 사라지는 현상이 발생하는 문제가 있어서,
2. not zero-centered
항상 양수이거나 음수인 경우에는 역전파 과정에서 부호가 안바뀌는 문제가 있다.
Zero-centering & Normalization & PCA & Whitening
각 Feature들이 동등한 기준으로 영향도를 보기 위해서 약간의 전처리를 해주는 작업.
이 중, PCA와 Whitening은 정보를 최대한 잃지 않으면서 차원을 축소해주는 작업

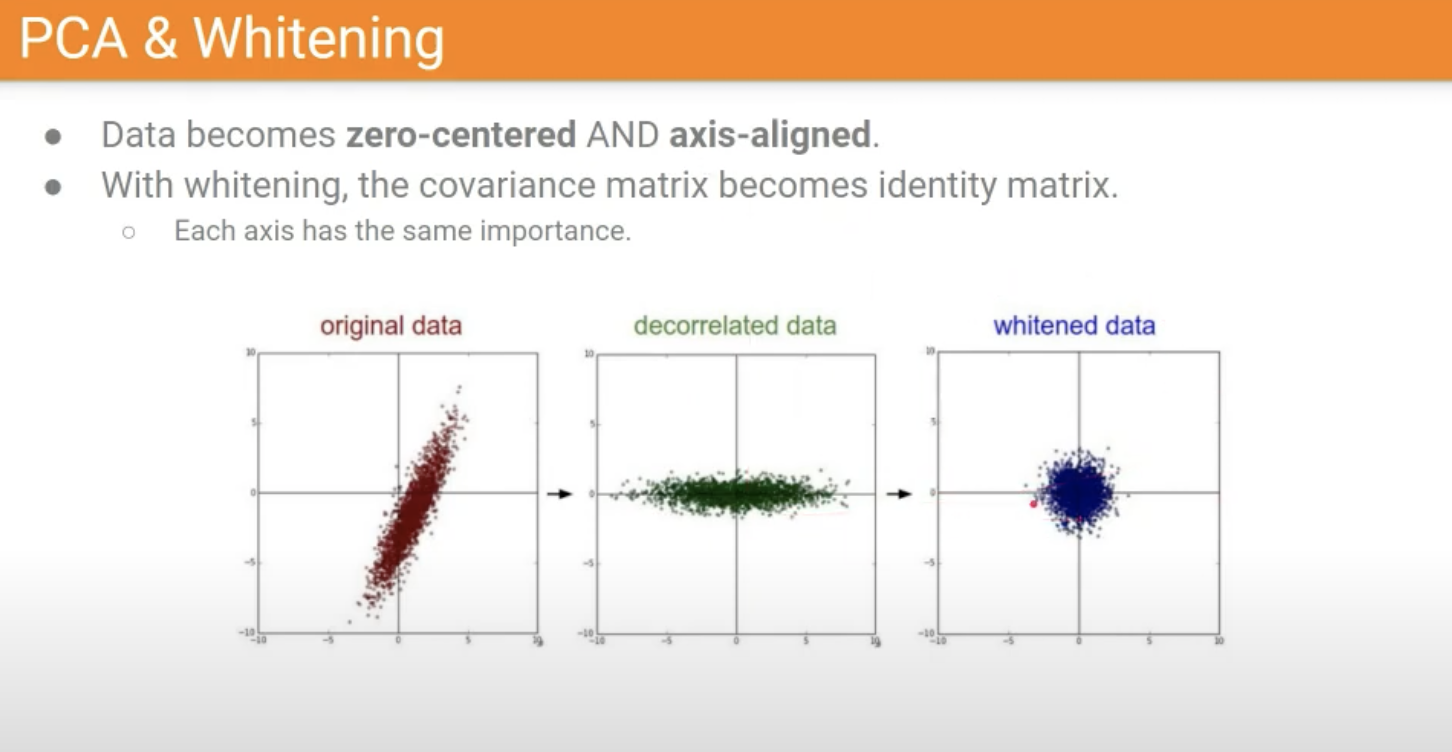
이 중, Whitening은 그림 상으로 이해하기가 어려워서 추가로 정리해보았다.
딥러닝에서 화이트닝(whitening)은 데이터 전처리 단계에서 적용되는 일반적인 기법 중 하나로, 입력 데이터의 공분산 구조를 단순화하는 것을 목표로 합니다. 이 과정에서 데이터 분포가 단위 분산을 갖도록 스케일링되고 상관관계가 제거되어 전체 데이터 세트가 희게(백색)되는 것처럼 보입니다.
화이트닝은 특히 이미지 및 신호 처리와 같은 분야에서 유용하며, 다음과 같은 2가지 주요 목표를 달성할 수 있습니다.
데이터의 스케일 조정: 화이트닝은 입력 데이터의 각 차원에 대해 평균을 0, 분산을 1로 만듭니다. 이렇게 하면 모델 학습이 더 원활하게 진행되고, 특정 변수의 스케일이 학습 결과에 우선순위를 두지 않게 됩니다.변수 간 상관 관계 제거: 화이트닝은 데이터 차원 간의 선형 상관 관계를 제거하여 특성 간의 독립성을 높입니다. 이로 인해 모델이 중복 학습을 방지하고, 복잡도가 낮아질 수 있습니다.
화이트닝 작업은 다음 단계로 진행됩니다.
입력 데이터의 평균을 계산하고 뺍니다. (평균이 0이 되도록 함)입력 데이터의 공분산 행렬을 계산합니다.공분산 행렬에 대해 고유값 및 고유벡터를 찾습니다. (고유값 분해)고유벡터와 고유값을 사용하여 디코딩 행렬을 구성합니다. 각 고유값의 역제곱근을 고유벡터에 곱합니다.원본 데이터와 디코딩 행렬을 곱하여 화이트닝된 데이터를 얻습니다.
이러한 화이트닝 작업을 통해 얻은 데이터는 학습 과정에서 신경망이 더 효율적으로 학습하도록 돕습니다. 그러나 이러한 전처리 작업은 계산 비용이 높을 수 있으며 딥러닝 모델의 경우, Batch Normalization과 같은 방법으로 학습 동안 내부 공변량 변화 문제를 해결하는 것이 더 일반적이고 효율적입니다.

Data Augmentation

- 사진은 정말 수많은 순간 중 한 순간의 장면을 담은 것이고, 우리는 특정 순간을 학습시키려는 것이 아니라 전반적인 시각적인 이해를 학습시키고 싶다.
- 따라서, 더 많은 데이터가 필요하고, 데이터를 더 많이 확보하기 위해서 약간의 수정하는 작업을 Data Augmentation이라고 한다.
→ 조금 수정해도 어차피 여자는 여자니까 이런 데이터로 학습하기도 함. - 예시
- 좌우, 상하반전
- Random Crops : 사진을 여러개로 자르는 거
- Scaling
- Color Jitter : 색상은 RGB뿐만 아니라 HSL이라는 기준이 있다. 이 HSL은 명도, 채도 등으로 이루어져있어서 수치를 바꿔도 색이 크게 바뀌지 않으면서 이미지 종류를 늘릴 수 있음.
Weight Initialization


초기화를 너무 작게 잡아도, 크게 잡아도 gradients들이 소멸되어서 학습시키기가 어렵다. 그래서, 적당한 값이 필요하다!
적절하게 초기화를 잡는 방법
1) xavier Initialization
- 너무 0으로 가도 안되고, 너무 1로도 가면 안되어서 찾다가 이렇게 해보니 잘되더라 해서 이걸로 해봄
→ 증명해보면 Input variance = output variance 에 유사하게 갈수록 간다.


2) kaiming/MSRA Initialization for ReLU

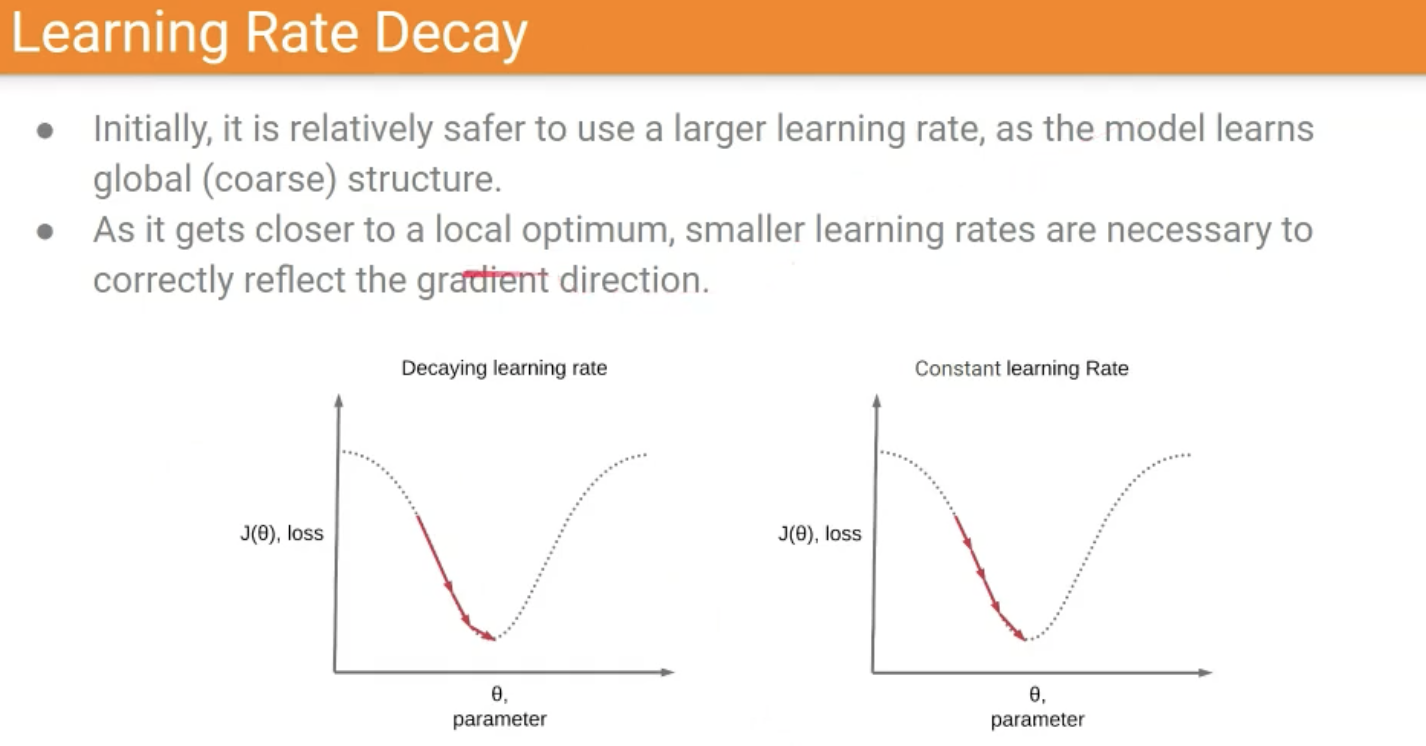
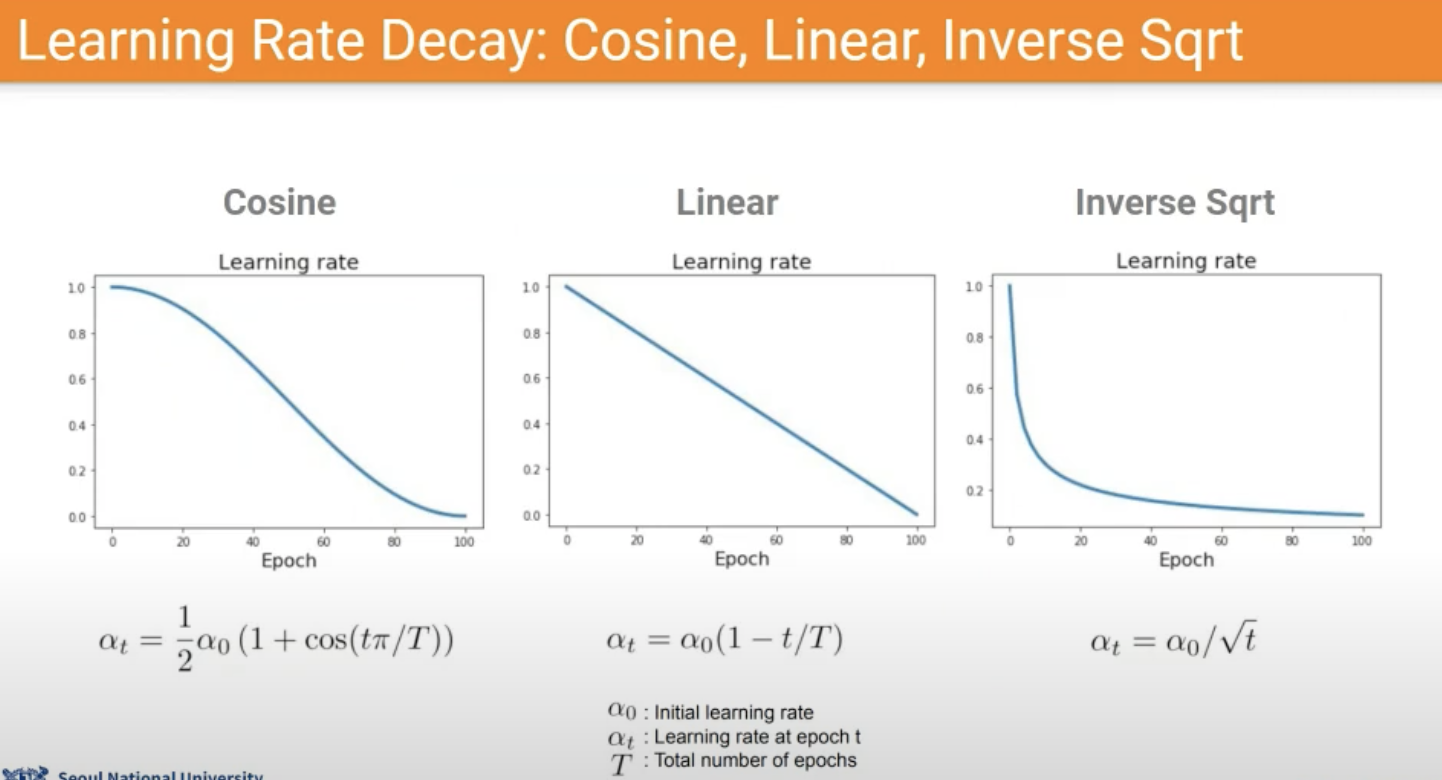
Learning rate schedule
매우매우 Heuristic하다.


7. Training Neural Networks 2
Overfitting
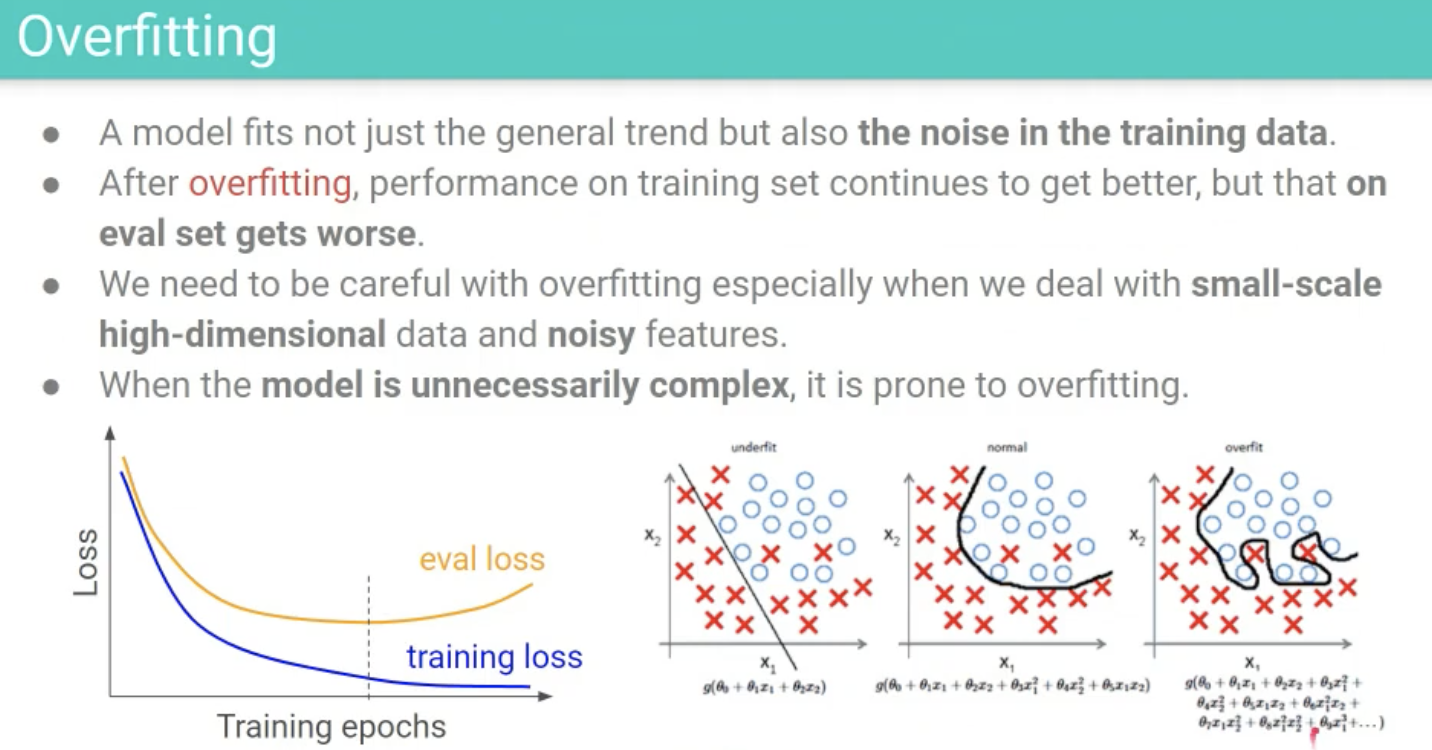
- overfitting이란 모델이 데이터의 Noise까지 다 학습해버리는 것.
- 일단 복잡한 것들로 만든 다음에 regularization을 하자는 방식으로 발전함 -> 목적함수에 추가적인 페널티를 넣어줌


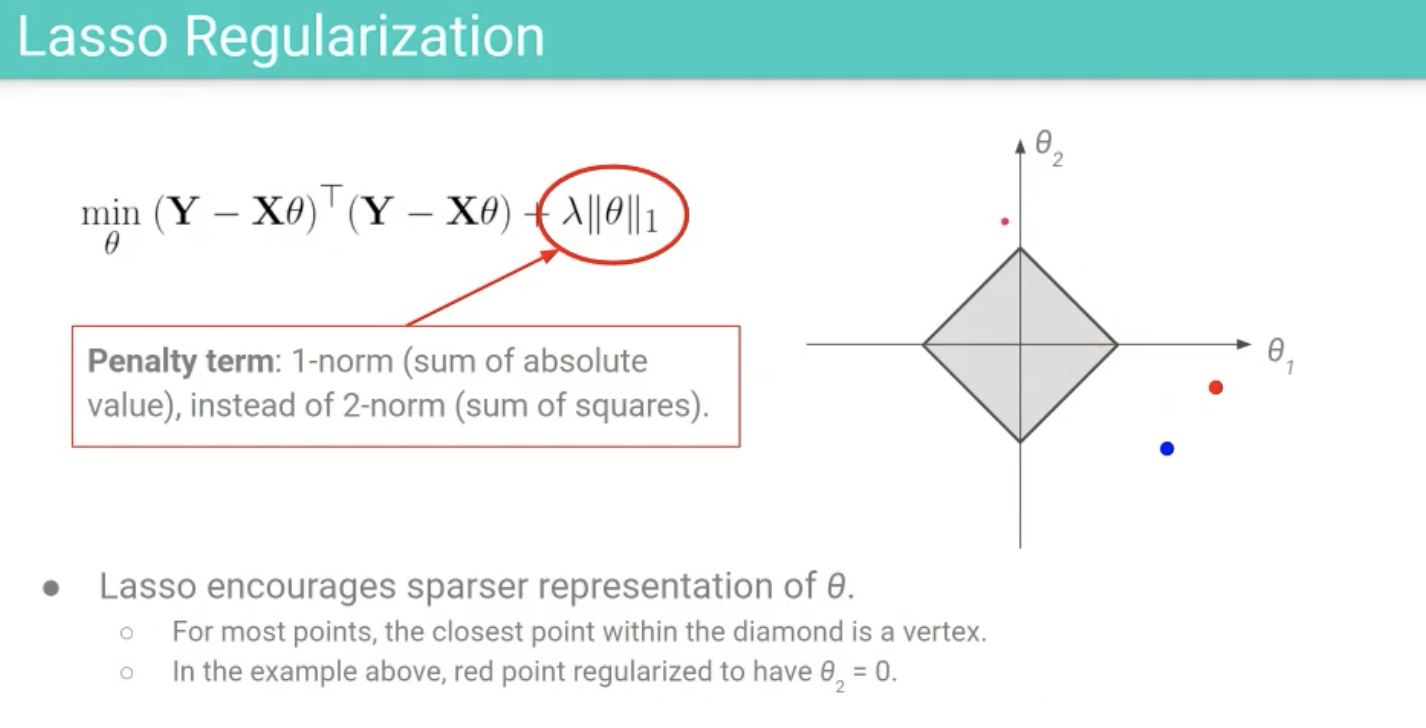
딥러닝에서의 Overfitting 방지 기법
1) Weight decay
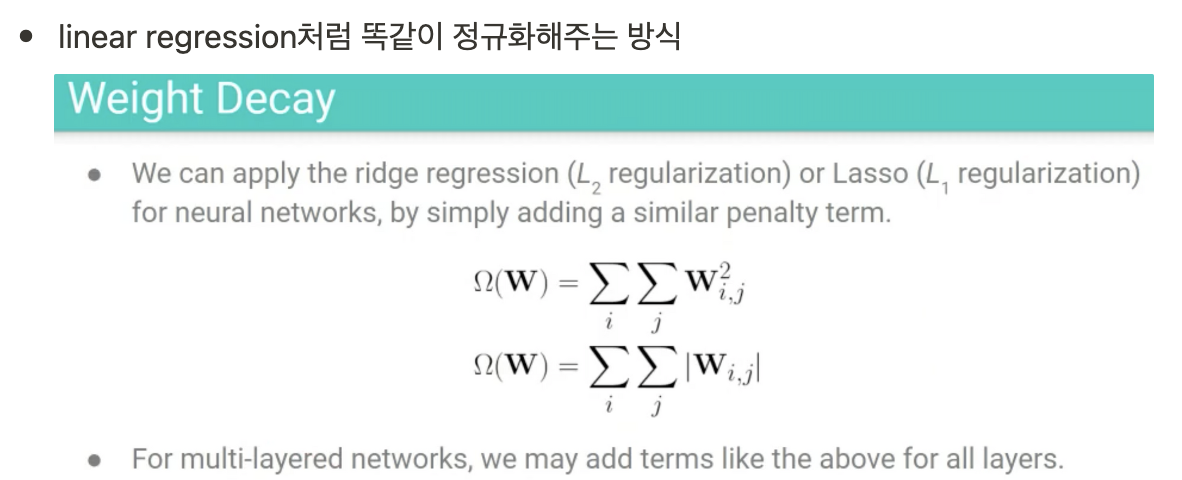
2) Early Stopping

3) Dropout
취지 : 고양이 귀만 보고 판단하게 오버피팅 될 수 있으니, 다양한 판별할수 있는 뉴런들을 학습시키는 것이 전체적으로 좋다.(고양이 귀를 가리면 고양이라고 못하는 케이스가 만들어지므로)

from torch import nn
def __init__(self, config, **kwargs):
self.linear = nn.Linear(224,32)
self.dropout = nn.Dropout(p=0.2)
def call(self, inputs, training = True):
embeddings = self.linear(inputs)
embeddings = self.dropout(embeddings)파이토치에서 dropout은 위와 같이 적용한다.(드롭아웃은 학습과정에서만 사용되고, 실제 추론과정에서는 전체 신경망을 활용한다.)
4) Cutout (관련 논문)

Optimization 개선
1) SGD의 문제점
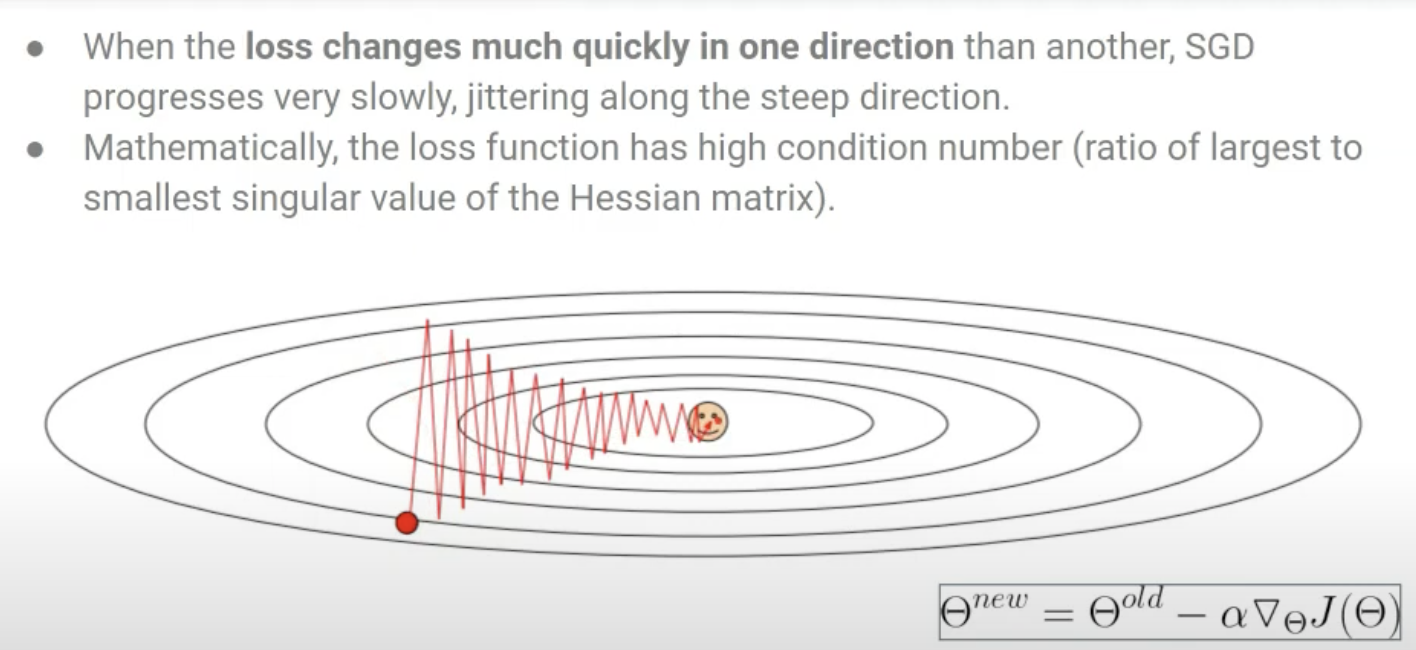
- Jittering 문제 : gradient는 각 방향별로 미분하기 때문에 오히려 최적점에 빠르게 도달하기 위한 축이 아니라, 다른 축에서 loss change가 더 크면 비효율적으로 움직인다.
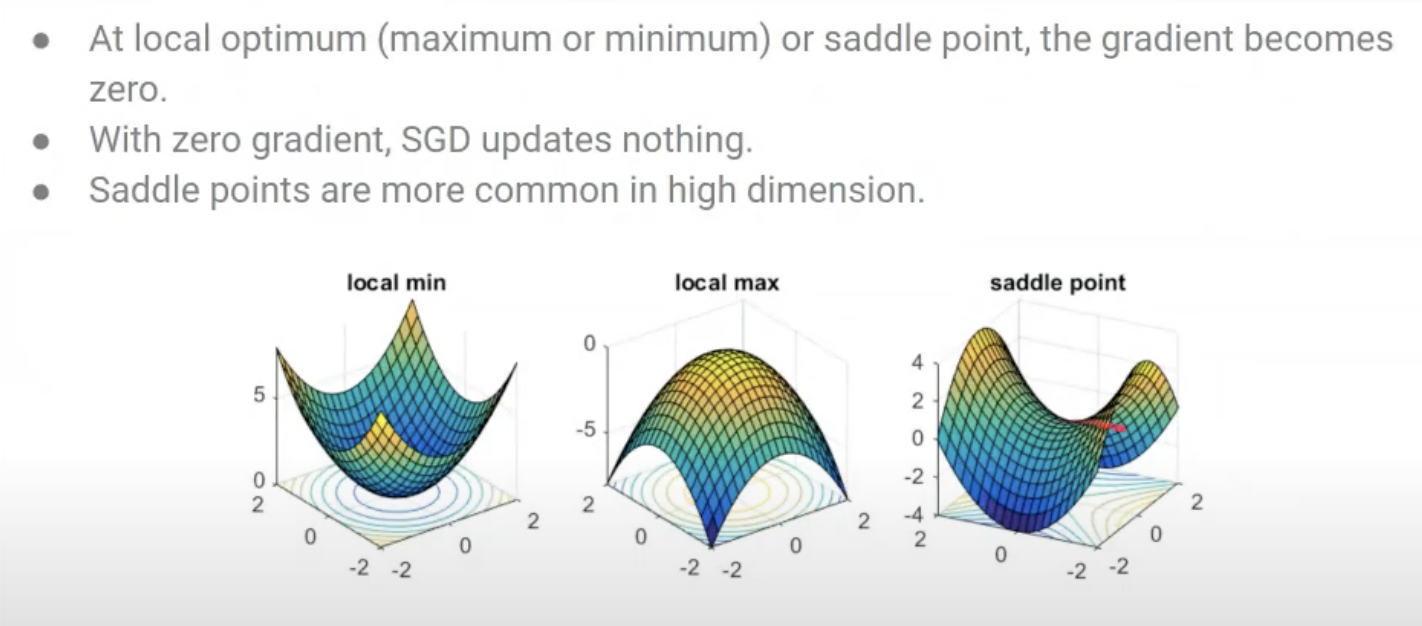
- Saddle point나 local optimum에서 더이상 업데이트가 안된다.
- 부정확한 gradient 추정 : 전체 데이터 대비 미니배치 사이즈 크기가 작은 경우에는 전체 데이터의 그라디언트 대표성을 띄지 못하는 문제가 있다.

2) Solution



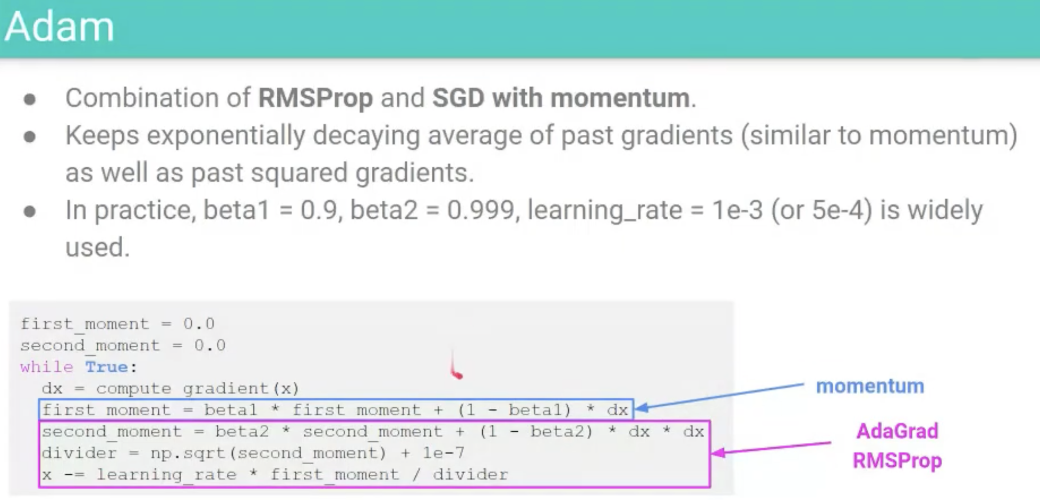

Batch Normalization
이 내용은, 별도의 블로그 글로 정리할 예정이라서 제외했습니다. 요즘은 layer norm을 많이 쓴다고 합니다.
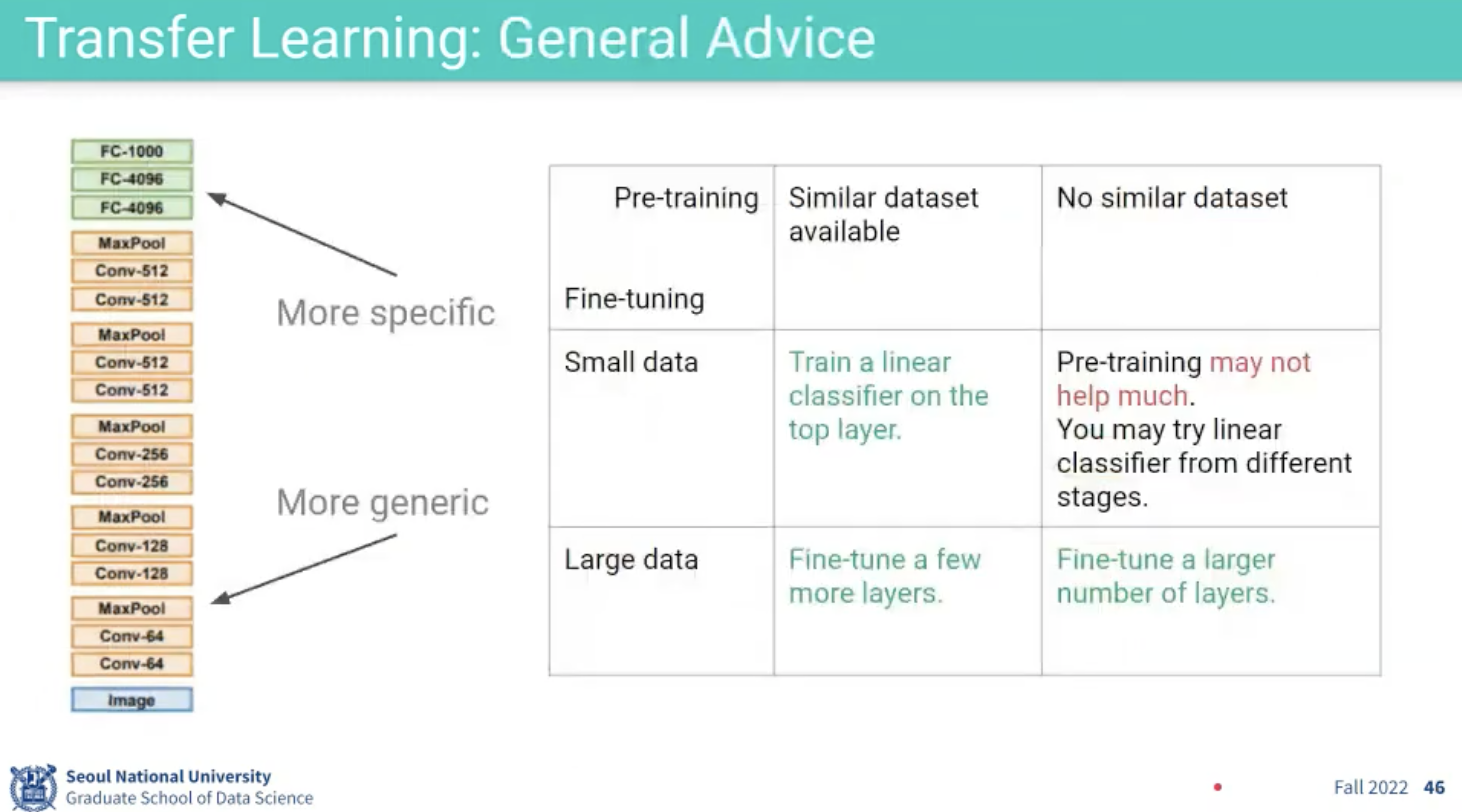
Transfer Learning
예시로, 우리가 10개 분류하던 모델을 학습시키다가 5개를 분류하는 모델을 새로 만들려고 한다고 하자. 이 때 5개 분류 모델의 데이터가 적다고 하자. 각 테스크의 특성이 다르기 때문에 High-level Features는 매우 다르겠지만, Low-level Features가 가진 정보들은 결국 이미지이기 때문에 비슷하다고 볼 수 있다. 그렇다면 우리는 데이터를 많이 쏟아부어서 학습시킨 10개 분류 모델의 앞단 신경망을 가져와서 5개 분류짜리 task를 수행하도록 학습시킬 수 있지 않을까?가 이 Transfer Learning의 시작이다.


주로, Freeze한다고 하는데, 이는 그 앞단의 gradient를 고정시킨다는 것을 의미한다.

'Machine Learning > 공부 기록' 카테고리의 다른 글
| 랭체인 튜토리얼 (0) | 2024.01.31 |
|---|---|
| [허깅페이스] Diffusers Tutorial - 모델 사용하기 (0) | 2023.12.30 |
| A/B 테스트에서의 양측검정 vs 단측검정 (0) | 2023.10.12 |
| 시각적 이해를 위한 머신러닝 3, 4강 (0) | 2023.09.28 |
| 시각적 이해를 위한 머신러닝 1~2강 (Machine learning for Visual Understanding) (0) | 2023.09.28 |

