이전에 Forward pass 코드 구현 이후로 역전파 개념과 학습에 필요한 작업들을 포함해서 코드를 작성해보았다. 이전 글은 여기서 볼 수 있고, 오늘은 최종적으로 인공신경망(Linear하게 쌓아올린 모델) 코드를 작성해보았다.
이전에 작성한 코드는 크게 3가지를 구현했고, 오늘은 추가로 4가지를 구현해보려고 한다.
weight 초기화신경망 구조 구성하기활성화 함수 넣어주기신경망을 통한 추론하기- loss 계산하기
- 역전파 구현하기
- gradient 업데이트
- 신경망 학습
기존 code는 우선 여기서 정리해보았고, 추가할 함수는 빈칸으로 놔두었다. 하나씩 채워보려고 한다.
#캐글 데이터셋에서 노트북 열기를 했을 때, 나오는 기본 설정
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename)) #코드 실행시에 pd.read_csv를 통해 가져올 파일 경로를 알려준다.
#데이터셋 가져오기
mnist_test = pd.read_csv('/kaggle/input/mnist-in-csv/mnist_test.csv')
mnist_train = pd.read_csv('/kaggle/input/mnist-in-csv/mnist_train.csv')
#train data, test data 세팅
y_train = mnist_train['label']
x_train = mnist_train.loc[:,mnist_train.columns != 'label']
y_test = mnist_test['label']
x_test = mnist_test.loc[:,mnist_test.columns != 'label']
#array 차원 확인하기
print(y_train.shape) #(60000,)
print(x_train.shape) #(60000, 784)
print(y_test.shape) #(10000,)
print(x_test.shape) #(10000, 784)
#Weight layer의 초기 임의값 넣어주기
def weight_initializer(neuron_layer_structure):
parameters = {}
for i in range(len(neuron_layer_structure)-1):
parameters['W' + str(i+1)] = np.random.randn(neuron_layer_structure[i],neuron_layer_structure[i+1]) #np.random.randn은
parameters['b' + str(i+1)] = np.random.randn(neuron_layer_structure[i+1])
return parameters
param = weight_initializer([784,128,64,32,16,10]) #예시로 넣을 신경망 모델링
param['W1'].shape #784X128
#활성화 함수 넣어주기
def sigmoid(x):
return 1/(1+np.exp(-x))
def forward_pass(x, parameters):
cache = {'a0': x}
for i in range(1,len(parameters)//2+1):
cache['z'+ str(i)] = cache['a' + str(i-1)] @ parameters['W' + str(i)] + parameters['b' + str(i)]
cache['a'+ str(i)] = sigmoid(cache['z'+ str(i)])
return cache
#실제로 한번 forward_pass 실행하기
cache_forward = forward_pass(x_train.loc[0,],param)
print(cache_forward['a1'].shape) #(128,)
print(cache_forward['a2'].shape) #(64,)
print(cache_forward['a3'].shape) #(32,)
print(cache_forward['a4'].shape) #(16,)
print(cache_forward['a5'].shape) #(10,)
###----------- 여기서부터 오늘 구현 -----------###
def compute_accuracy(x_val, y_val, parameters):
"""테스트 데이터로 예측값의 성능을 계산하는 함수"""
return np.mean(predictions)
def compute_loss(x_val, y_val, parameters):
"""학습 데이터에서 현재 모델의 손실을 계산하는 함수"""
return loss / len(x_val)
def back_prop(prediction, y, cache, parameters):
"""역전파 함수"""
return gradients
def update(parameters, gradients, alpha, m):
return parameters
def train_nn(X_train, Y_train, X_test, Y_test, neurons_per_layer, epoch, alpha):
"""학습"""
return loss_list, parameters
# 테스트 코드
neurons_per_layer = [784, 128, 64, 10]
parameters = initialize_parameters(neurons_per_layer)
loss_list, parameters = train_nn(X_train, Y_train, X_test, Y_test, neurons_per_layer, 30, 500)
loss 계산하기
일반적인 프로그래밍 방식과 다르게 딥러닝은 모델이 예측한 값과 실제 정답의 차이를 줄여나가는 방식으로 학습해간다. 따라서 우리는 모델이 예측을 할 때마다 그 예측이 실제 정답과 얼마나 다른지 측정하는 함수가 필요하다.
이번에는 MSE를 활용하려고 한다.
def compute_loss(x_val, y_val, parameters):
"""학습 데이터에서 현재 모델의 손실을 계산하는 함수"""
loss = 0
for x, y in zip(x_val, y_val):
output, _ = feed_forward(x, parameters) # output만 가져오기 위한 목적)
loss += np.mean((output - y)**2) / 2 # MSE식을 그대로 적용
return loss / len(x_val) #평균 loss를 줄이는 방식이다.
역전파 구현하기
앞에서 우리는 loss_function의 미분의 반대방향으로 값을 바꿔가면서 정답을 잘 맞출 수 있는 가중치를 찾아간다고 했다. 이를 위해 역전파 과정이 필요한데 수식에 대한 정리는 아래 good note를 통해서 작성해보았다. 파란 글씨로 된 식이 우리가 코드에서 활용하려는 식이다.
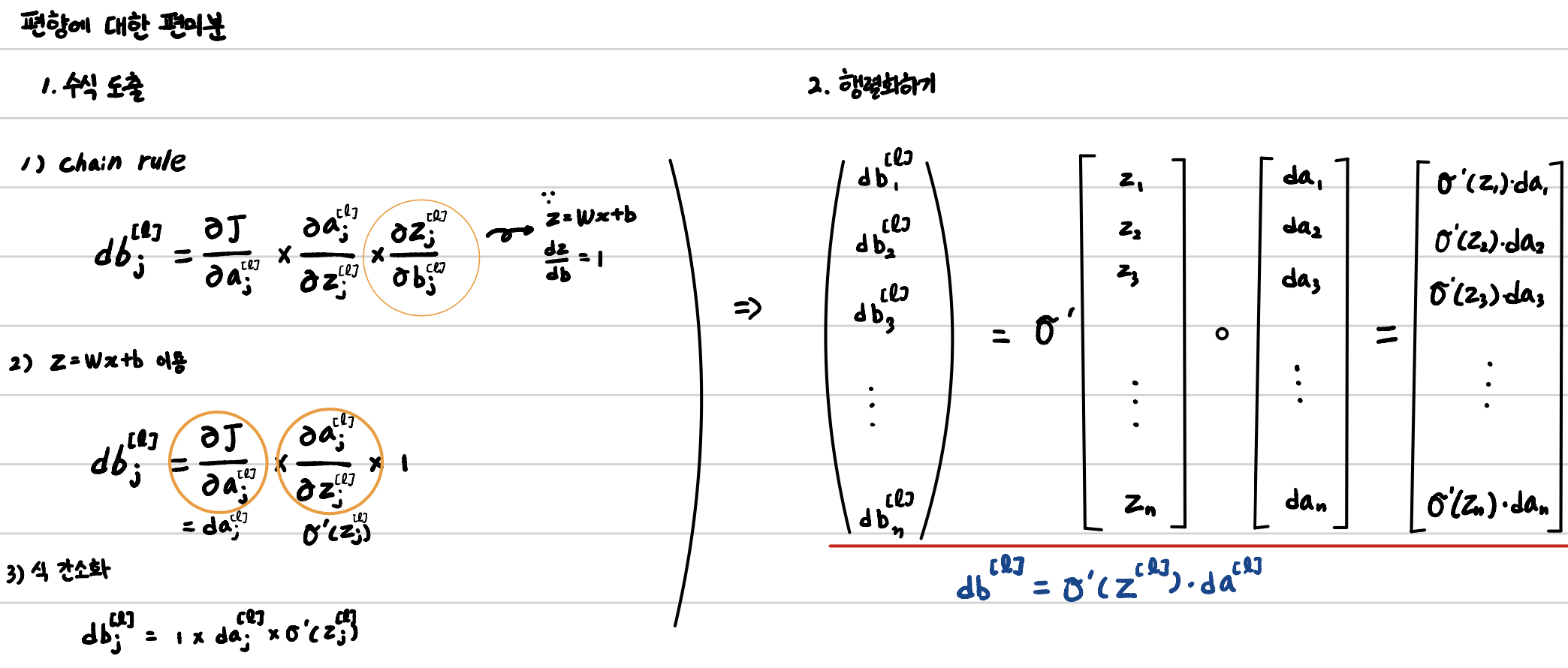


이걸 활용해서 코드를 작성해보면 아래와 같고, 주석을 통해 추가 설명을 덧붙였다.
def back_prop(prediction, y, cache, parameters):
"""역전파 함수"""
gradients = {} #parameter처럼 그라디언트 역시 dictionary 형태로 정리했다.
L = len(cache) // 2
da = (prediction - y) / y.shape[0]
# 앞서 식에서 보다시피 모든 da는 L-1에서 이루어지기 때문에 L(손실함수에 대한 y_pred 미분)에서의 값을 지정해준 것이다.
for layer in range(L, 0, -1):
# 편미분 계산에 필요한 데이터 설정하기
a_prev = cache['a' + str(layer-1)]
z = cache['z' + str(layer)]
W = parameters['W' + str(layer)]
# 가중치와 편향 + 전 층 뉴런 출력에 대한 편미분 계산(상단 굿노트의 파란색 글씨의 선)
db = da * d_sigmoid(z)
dW = np.outer(db, a_prev)
da = W.T @ db
# 계산한 편미분 값들을 저장
gradients['dW' + str(layer)] = dW
gradients['db' + str(layer)] = db
# 계산한 편미분 값들 리턴
return gradients
가중치 업데이트
이제 우리는 미분값의 반대방향으로 가중치를 조금씩 이동시켜주는 작업이 필요하다. 이를 위한 함수는 아래와 같다. 경사하강법 방식을 그대로 사용하였기 때문에 별도의 설명은 없다.
def update(parameters, gradients, alpha, m):
"""계산한 경사로 가중치와 편향을 업데이트 하는 함수"""
L = len(parameters) // 2
for layer in range(1, L+1):
parameters['W'+str(layer)] -= alpha * gradients['dW'+str(layer)] / m #평균 하강법을 사용하기 때문에 m을 나눠주었다.
parameters['b'+str(layer)] -= alpha * gradients['db'+str(layer)] / m
return parameters
신경망 학습 시키기
이제 우리의 데이터를 직접 넣고 반복하는 작업을 거치면 된다. 따라서 이 함수에는 for문이 들어간다.
def train_nn(X_train, Y_train, X_test, Y_test, neurons_per_layer, epoch, alpha):
"""신경망을 학습시키는 함수"""
parameters = initialize_parameters(neurons_per_layer)
loss_list = []
m = X_train.shape[0]
# epoch 번 경사 하강을 한다
for i in range(epoch):
parameters_copy = parameters.copy()
# 모든 이미지에 대해서 경사 계산 후 평균 계산
for x, y in zip(X_train, Y_train):
prediction, cache = feed_forward(x, parameters)
gradients = back_prop(prediction, y, cache, parameters)
parameters_copy = update(parameters_copy, gradients, alpha, m)
# 가중치와 편향 실제로 업데이트
parameters = parameters_copy
loss_list.append(compute_loss(X_train, Y_train, parameters))
print('{}번째 경사 하강, 테스트 셋에서 성능: {}'.format(i+1, round(compute_accuracy(X_test, Y_test, parameters), 2)))
return loss_list, parameters
최종적으로 정리해보면 코드는 아래와 같다.
#캐글 데이터셋에서 노트북 열기를 했을 때, 나오는 기본 설정
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename)) #코드 실행시에 pd.read_csv를 통해 가져올 파일 경로를 알려준다.
#데이터셋 가져오기
mnist_test = pd.read_csv('/kaggle/input/mnist-in-csv/mnist_test.csv')
mnist_train = pd.read_csv('/kaggle/input/mnist-in-csv/mnist_train.csv')
#train data, test data 세팅
y_train = mnist_train['label']
x_train = mnist_train.loc[:,mnist_train.columns != 'label']
y_test = mnist_test['label']
x_test = mnist_test.loc[:,mnist_test.columns != 'label']
#array 차원 확인하기
print(y_train.shape) #(60000,)
print(x_train.shape) #(60000, 784)
print(y_test.shape) #(10000,)
print(x_test.shape) #(10000, 784)
#Weight layer의 초기 임의값 넣어주기
def weight_initializer(neuron_layer_structure):
parameters = {}
for i in range(len(neuron_layer_structure)-1):
parameters['W' + str(i+1)] = np.random.randn(neuron_layer_structure[i],neuron_layer_structure[i+1]) #np.random.randn은
parameters['b' + str(i+1)] = np.random.randn(neuron_layer_structure[i+1])
return parameters
param = weight_initializer([784,128,64,32,16,10]) #예시로 넣을 신경망 모델링
param['W1'].shape #784X128
#활성화 함수 넣어주기
def sigmoid(x):
return 1/(1+np.exp(-x))
def forward_pass(x, parameters):
cache = {'a0': x}
for i in range(1,len(parameters)//2+1):
cache['z'+ str(i)] = cache['a' + str(i-1)] @ parameters['W' + str(i)] + parameters['b' + str(i)]
cache['a'+ str(i)] = sigmoid(cache['z'+ str(i)])
return cache
#실제로 한번 forward_pass 실행하기
cache_forward = forward_pass(x_train.loc[0,],param)
print(cache_forward['a1'].shape) #(128,)
print(cache_forward['a2'].shape) #(64,)
print(cache_forward['a3'].shape) #(32,)
print(cache_forward['a4'].shape) #(16,)
print(cache_forward['a5'].shape) #(10,)
###----------- 여기서부터 오늘 구현 -----------###
def compute_accuracy(x_val, y_val, parameters):
"""테스트 데이터에서 예측값들의 성능을 계산하는 함수"""
predictions = []
for x, y in zip(x_val, y_val):
output, _ = feed_forward(x, parameters)
pred = np.argmax(output)
predictions.append(pred == np.argmax(y))
return np.mean(predictions)
def compute_loss(x_val, y_val, parameters):
"""학습 데이터에서 현재 모델의 손실을 계산하는 함수"""
loss = 0
for x, y in zip(x_val, y_val):
output, _ = feed_forward(x, parameters) # output만 가져오기 위한 목적)
loss += np.mean((output - y)**2) / 2 # MSE식을 그대로 적용
return loss / len(x_val) #평균 loss를 줄이는 방식이다.
def back_prop(prediction, y, cache, parameters):
"""역전파 함수"""
gradients = {} #parameter처럼 그라디언트 역시 dictionary 형태로 정리했다.
L = len(cache) // 2
da = (prediction - y) / y.shape[0]
# 앞서 식에서 보다시피 모든 da는 L-1에서 이루어지기 때문에 L(손실함수에 대한 y_pred 미분)에서의 값을 지정해준 것이다.
for layer in range(L, 0, -1):
# 편미분 계산에 필요한 데이터 설정하기
a_prev = cache['a' + str(layer-1)]
z = cache['z' + str(layer)]
W = parameters['W' + str(layer)]
# 가중치와 편향 + 전 층 뉴런 출력에 대한 편미분 계산(상단 굿노트의 파란색 글씨의 선)
db = da * d_sigmoid(z)
dW = np.outer(db, a_prev)
da = W.T @ db
# 계산한 편미분 값들을 저장
gradients['dW' + str(layer)] = dW
gradients['db' + str(layer)] = db
# 계산한 편미분 값들 리턴
return gradients
def update(parameters, gradients, alpha, m):
"""계산한 경사로 가중치와 편향을 업데이트 하는 함수"""
L = len(parameters) // 2
for layer in range(1, L+1):
parameters['W'+str(layer)] -= alpha * gradients['dW'+str(layer)] / m #평균 하강법을 사용하기 때문에 m을 나눠주었다.
parameters['b'+str(layer)] -= alpha * gradients['db'+str(layer)] / m
return parameters
def train_nn(X_train, Y_train, X_test, Y_test, neurons_per_layer, epoch, alpha):
"""신경망을 학습시키는 함수"""
parameters = initialize_parameters(neurons_per_layer)
loss_list = []
m = X_train.shape[0]
# epoch 번 경사 하강을 한다
for i in range(epoch):
parameters_copy = parameters.copy()
# 모든 이미지에 대해서 경사 계산 후 평균 계산
for x, y in zip(X_train, Y_train):
prediction, cache = feed_forward(x, parameters)
gradients = back_prop(prediction, y, cache, parameters)
parameters_copy = update(parameters_copy, gradients, alpha, m)
# 가중치와 편향 실제로 업데이트
parameters = parameters_copy
loss_list.append(compute_loss(X_train, Y_train, parameters))
print('{}번째 경사 하강, 테스트 셋에서 성능: {}'.format(i+1, round(compute_accuracy(X_test, Y_test, parameters), 2)))
return loss_list, parameters
# 테스트 코드
neurons_per_layer = [784, 128, 64, 10]
parameters = initialize_parameters(neurons_per_layer)
loss_list, parameters = train_nn(X_train, Y_train, X_test, Y_test, neurons_per_layer, 30, 500)'Machine Learning > 개념 정리' 카테고리의 다른 글
| Hyperparameter Search Optimization (1) | 2023.11.30 |
|---|---|
| Tree Model 정리 (0) | 2023.11.29 |
| 딥러닝 학습 - parameter와 hyper-parameter (1) | 2023.09.18 |
| back-propagation 개념 (0) | 2023.09.15 |
| Forward Pass code의 수학적 이해와 code 구현하기 (0) | 2023.09.14 |



