의미있는 논문을 해야하나 어떤 것을 할까 생각하다가, 우선은 최근에 알게 된 논문부터 해보기로 했다. 논문 리뷰 목적은 기본적으로 나중에 내가 다시 영어 논문을 찾아보지 않아도 바로 이 블로그만 봐도 전체적인 내용을 파악할 수 있게 하기 위함이고, 논문별 인사이트, 논문간의 연결점들은 따로 스프레드 시트로 정리하려고 하고 있는데 이건 어떻게 블로그에 공유할 수 있을지는 좀 더 고민해보려고 한다.
Learned
- 최근 LLM 모델들의 대부분은 결국 Cost - Efficiency 문제를 해결하는데 집중하는 것으로 보인다.(Parameter, Computation Cost) LLM을 만드는 기업은 소수의 빅테크 기업이 독점할 것이고, 대부분의 개발자나 회사는 그 모델을 파인튜닝해서 사용할텐데 그 관점에서 다양한 인사이트를 배워볼 수 있어서 좋았다.
- PEFT(Parameter Efficient Fine Tuning) 기법들의 장단점과 원리를 명확하게 비교할 수 있어서 좋았다. (해당 논문 추천)
- 단순히 파라미터를 줄이는 것이 중요한게 아니라 병렬 학습이 가능한지, Inference Efficiency까지 고려하는 것 또한 비용 측정 관점에서 중요하다.
Summary

LoRA: Low-Rank Adaptation of Large Language Models
서론
(배경 및 문제)
많은 NLP 어플리케이션들은 하나의 큰, pre-trained 모델을 활용해서 다양한 하위 테스크들을 수행해왔다. 이는 보통 pre-trained model의 전체 파라미터를 업데이트하는 fine-tuning을 통해서 이루어지는데 이 모델의 단점은 새롭게 만들어진 모델조차도 기존 모델 만큼의 많은 파라미터를 가지고 있어야 한다는 점이다.
하나의 Large Model에게 시킬 task가 20개이고 이를 각각 파인튜닝한다고 하면, 20개의 Large model만큼의 파라미터를 가지고 있다는 것이다.(이전에는 이것이 문제가 없지만 오늘날 Large model의 파라미터들은 몇천억개의 파라미터를 가지고 있다. 이게 20개, 30개라고 하면 꽤 큰 문제일 수 있다.) 이를 해결하기 위해서 새로운 테스크에 대해서 일부 파라미터만 수정하거나, 외부 모듈을 학습하는 방식을 활용해왔지만 실제로 이런 방식들은 fine-tuning이 내는 성과에 미치지 못했다.
(논문 아이디어)
1. Why?
"Learned over-parameterized models in fact reside on a low intrinsic dimension"
논문에서는 위에서 영감을 얻었다고 했는데, 한국어로 번역을 막 해보면 "학습된 과다 매개변수화 모델들은 실제로는 그 복잡성에 반하는 내재적으로 낮은 차원에 위치한다."이다. 해석해보면, 우리가 해결하려는 문제 대비 over-parameterized로 학습되었다는 것은 그렇게 많은 파라미터를 활용하지 않아도, 일부 중요한 저차원(더 작은 파라미터)으로도 설명할 수 있다.라는 이야기이다. 파라미터와 차원이 같은 말은 아니기는 하다. 해석을 위해 파라미터를 줄인다 = 저차원이라고 얘기를 했지만 단순히 파라미터를 줄이는 개념이라기보다는 파라미터가 표현하는 벡터의 차원을 줄인다는 의미에 가깝다.
위의 문제에 대입해보면, 우리가 해결하려는 downstream task(LLM 모델을 통해 시키려는 일들)을 거대한 파라미터를 가진 LLM에게 시키기에는 LLM 모델은 over-parameterized 모델이라고 볼 수 있고, 우리가 over-parameterized된 모델의 Parameter를 다 수정하기보다는 차원을 줄여서 parameter를 해결해보자는 것이 이 논문의 접근방식이다.
2. How?
위에서 우리는 모델의 차원을 줄이자는 이야기를 했다. 그럼 이를 어떻게 구현할까? 아래 그림을 보면 직관적으로 이해할 수 있다.

여기서 3번이 논문의 핵심 키포인트인데, 이는 그림을 통해서 보면 이해하기 쉽다.

위 도식은 low rank decomposition matrices라는 개념을 활용했는데 앞서 설명처럼 하위 테스크를 수행하기에는 현재의 파라미터는 너무 over-parameterized되었다. 저차원만으로도 이러한 테스크를 수행하는 능력을 학습시킬 수 있다는 인사이트를 활용해, 현재 모델이 가진 차원을 우측과 같이 두개의 저차원 행렬 곱셈으로 분해하고, 이 두 개의 행렬의 가중치를 학습시켜보자가 3번 단계가 의미하는 바이다.
3. 장점
- 우선은 pre-trained model이 가진 가중치(학습한 지능)를 그대로 활용하면서 각 테스크에 fit된 작은 Lora Module들을 활용할 수 있고, 모델 자체가 작기 때문에 쉽게 switch 할 수 있다.
- 파라미터 수가 작아져서, gradient 계산 등에 있어서 하드웨어 장벽을 낮추고 학습을 더 효율적으로 할 수 있다.
- inference latency는 파라미터 수나 복잡성에 비례하는데, 단순 기존 웨이트에 더해주는 작업만 추가되는 이 방식에서는 latency가 발생되지 않는다는 장점이 있다.
Problem Statement (문제 정의 = 목적함수 정의)
우리가 목표함수와 관계없이 적용가능하기 때문에 여러 유즈케이스 중에 이번 논문에서는 language modeling을 활용해보자.

파인튜닝 모델의 목적함수는 전체 파라미터를 바꾸는 것이었다면, LoRA 개념을 도입하게 되면 우리가 찾을 가중치의 해의 갯수가 감소한 것을 식에서 볼 수 있다.

문제 해결의 필요성(현재 이 문제들을 기존의 연구에서는 어떻게 해결하고 있는지?)
이 문제가 전혀 새로운 것은 아니다. 이미 파라미터, 컴퓨팅 효율적인 방법을 찾기 위해 많은 연구들이 있었는데 adapter layers나 input layer activations이 Language modeling 관점에서 가장 유명한 접근 방법이다. 하지만 이 전략 모두 모델이 매우 크거나, 레이턴시가 중요한 문제에 있어서는 한계가 있다. (찾다보니 이 모델을 Parameter Efficient Fine Tuning, PEFT라고 한다.)

쉽게 비교해볼 수 있는 도식을 정리해두었는데, a와 b 방법 모두 기존의 추론, 학습 방식에 직렬적으로 한단계가 추가되는 방식이라는 점을 기억하고 넘어가면 이후의 해당 솔루션의 단점을 이해하기 쉽다.
1) Adapter Layers Introduce Inference Latency
- 앞서 말했던 것처럼, 직렬적으로 Layer가 추가되기 때문에 Adapter layer가 추론이 안되면 다음 학습으로 넘어가지 않기 때문에 이 레이어에서 작은 파라미터를 쓰더라도 추론 지연이 일어날 수 밖에 없다.

2) Directly Optimizing the Prompt is Hard
- 새롭게 학습시키는 task가 추가되는 것인데, 이 성능이 직접 Layer에 파라미터를 추가하는 것 대비해서 성능이 좋지 않고 결국 input에다가 prompt를 위한 자리가 필요해서 input size가 작아지는 문제가 있다.
Our Method
저차원의 행렬로 변경하기
1. 초기 layer 설정

우리는 기존 모델의 가중치인 W0는 freeze하고 B와 A라는 두개의 분해된 행렬을 만든다. 이 때 A는 random Gaussian 초기화를 통해서 행렬의 값을 채워주고, B는 모든 값이 0인 행렬로 만들어준다. 이렇게 함으로써, 초기 학습의 시작은 기존 모델과 동일하게 만들어준다.( h = W0x )
A, B의 차원은 각각 아래와 같다.
- Dimension(A) : Dimension(r) X Dimension(model_row)
- Dimension(B) : Dimension(model_column) X Dimension(r)
- r의 조건 << min(model_column, model_row) #차원을 줄이는 것이 목적이므로 논문에서는 모델 차원보다 작은 값을 지정해준다.
2. Generalization of Full Fine-tuning
일반적으로 파인튜닝이라고 하면, 전체 모델 파라미터의 부분집합들을 트레이닝하는 것을 의미한다. LoRA는 전체 웨이트의 업데이트를 필요로 하지 않는다. 하지만 LoRA의 차원인 r을 모델 수준으로 키우면 이는 전체 모델을 파인튜닝하는 것과 동일하기 때문에 Full Fine-tuning까지 시킬 수 있는 일반적인 방법론이다.
3. No additional Inference Latency
우리가 다른 Downstream task를 하려고 하면, W0는 그대로 유지하고 BAx만 제거하고 또다른 task에 학습된 BAx만 추가시키면 된다. 이를 통해 우리는 파인튜닝 모델과 비교했을 때 추론하는 동안 추가적인 latency를 만들지 않는다.
LoRA를 Transformer에 적용해보기
트랜스포머 모델은 LayerNorm, MLP layer, biases 등 여러가지가 있지만 이번 연구에서는 parameter-efficiency를 위해 Attention layer에만 적용했다.
가장 중요한 이점은 메모리와 스토리지 사용량 감소이다. Adam으로 학습된 대형 Transformer의 경우 고정 파라미터에 대한 optimizer 상태를 저장할 필요가 없으므로 VRAM 사용량을 최대 2/3까지 줄인다.(GPT-3 175B의 경우 학습 중 VRAM 소비 : 1.2TB -> 350GB)
추가로 r = 4인 상황에서 query와 key projection 행렬만 튜닝되면 약 10,000배 (350GB에서 35MB로) 감소한다. 이를 통해 훨씬 적은 수의 GPU로 학습하고 입출력 병목 현상을 피할 수 있다.
또 다른 이점은 모든 파라미터가 아닌 LoRA 모델의 가중치만 갈아끼움으로써 훨씬 저렴한 비용으로 배포 중에 task 사이를 전환할 수 있다. 이를 통해 사전 학습된 가중치를 VRAM에 저장하는 시스템에서 즉석에서 교환할 수 있는 많은 맞춤형 모델을 생성할 수 있다. 또한 대부분의 파라미터에 대한 기울기를 계산할 필요가 없기 때문에 전체 fine-tuning에 비해 GPT-3 175B에서 학습하는 동안 25% 속도 향상을 보인다.
물론 한계점이 있다. 예를 들어 서로 다른 테스크들을 배치 단위로 처리하려고 한다면 가중치를 테스크별로 바꿔줘야하는데 이 때 inference latency가 발생한다.
Empirical Experiments
모델에서 비교대상으로 활용한 Fine-tuning 방법들을 아래와 같이 정리해두었다.

이제 실제 결과들을 살펴봐야하는데 사실 결과는 논문 특성상 당연히 베이스라인 대비 좋은 성능을 보였기 때문에 간략하게 캡처해서 올리려고 한다.



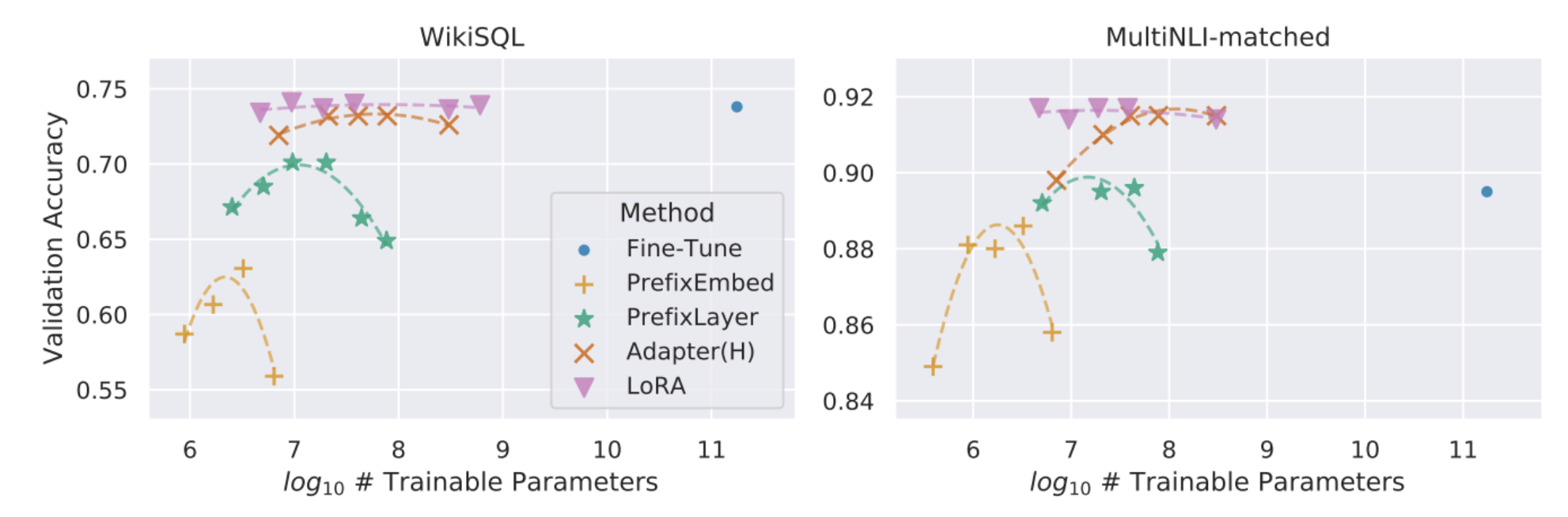
다른 방법론과 다르게 LoRA는 파라미터가 커짐에 따라 성능 하락의 문제는 발생하지는 않는다. (scalable)
Understanding the Low-Rank Updates (낮은 차원의 학습에 대한 고찰)
연구를 하며, 추가적으로 아래 3가지 질문을 함께 고민해보았다.
1. parameter의 제약이 있다면, 전체 모델의 layer 중에 어떤 layer에 LoRA를 적용하는 것이 좋을까?

- 트랜스포머 모델 기준) 단일 가중치만 수정해야한다면 모델에 대해서는 Wq, Wk가 제일 성능이 낮았으며, 여러개의 가중치 조합에 적용했을 때에는 Wq,Wv가 가장 성능이 좋았다. 전체 조합 중에서는 q,k,v,o를 모두에 LoRA를 적용한 것이 가장 효과적이었다.
2. LoRA에 있어서 통용되는 최적화된 차원이 있을까?(우리가 어떤 차원으로 줄여야 Task를 수행하면서도 효율적으로 parameter를 줄일 수 있을까?)

기본적으로 r이 낮아도 충분히 성능이 나온다는 것을 볼 수 있다. 논문에서는 Grassman Distance를 활용했는데, 앞서 우리가 LoRA라는 것은 일종의 벡터라는 것을 볼 수 있다. 벡터는 일종의 공간을 만들어내는데, r = 1 ~ 64에 따라 결과값으로 나오는 벡터가 만들어낸 공간 간의 거리가 가깝다면 결국은 이 task를 동일하게 수행할 수 있는 능력을 가지고 있다는 것을 의미한다.
이 공식과 그래프는 아래와 같다.


3. 사전학습된 가중치와 task에 specific한 w(LoRA)는 어떤 관계가 있을까?
이는 사전학습된 모델의 가중치를 W(LoRA)에 투사시켜보면 된다. 어떻게 투사시켜볼 수 있을까? 우리는 이 때 특이값 분해를 활용한다.
논문에서는 이렇게 구한 값과 w(LoRA)와 ramdom matrix의 값을 비교해서 인사이트를 뽑아냈다.

1) Random보다 확실히 상관관계가 있다.
2) 특이값 분해 관점에서 top-1 singular 방향이 아닌 W에서 강조되지 않은 방향의 벡터의 방향을 향하고 있다.(W에서 잘 설명하지 못하는 영역을 담당한다.)
3) 벡터가 특정 방향으로 증폭되는데 그 증폭의 값이 매우 크다.
Conclusion And Future Work
LLM을 파인튜닝하는 것은 하드웨어나 저장/전환 비용 관점에서 매우 비싸다. LoRA를 제안함으로써 우리는 inference latency나 인풋의 길이를 축약시키는 문제를 일으키지 않는 효율적인 layer 추가 전략을 제안했다. 하지만 후속 연구의 방향은 꽤 많다.
1) LoRA는 다른 효율적인 Adaptation Method들과 결합해서 더 개선될 수 있다.
2) 여전히 fine-tuning의 메커니즘이 명확하게 규명되지는 않았다. 어떻게 학습된 feature들이 downstream work를 잘 수행하게끔 변형될까? LoRA는 모든것을 파인튜닝하는 것보다 훨씬 더 이 메커니즘을 규명하는 답을 찾기 쉽게 만들어 줄 것이라고 생각한다.
3) 우리는 여전히 LoRA를 적용하는데 가중치 선택에 휴리스틱한 방법들을 사용하고 있다.
4) 우리가 저차원의 신경망을 추가해서 더하는 개념은 LLM자체도 차원을 줄일 수 있다. 이것또한 후속으로 시도해볼 수 있지 않을까 생각이 든다.
'Machine Learning > 논문 리뷰' 카테고리의 다른 글
| 디퓨전 모델 논문 리뷰 : Denoising Diffusion Probabilistic Models (0) | 2023.09.23 |
|---|---|
| [RLHF] Deep Reinforcement Learning from Human Preference 논문 리뷰 (0) | 2023.09.19 |

