생성 AI 분야에서 모델이 학습하는 것은 우리가 만들어내려는 이미지의 "분포"를 학습하는 것이다. 이 부분이 가장 중요하고 이번 장에서 이 개념을 인지하고 보는 것이 가장 중요하다. WGAN의 경우에는 특히 분포간의 거리를 측정하는 와서스테인 손실함수가 나오는데 사실 이해하는데 오래 걸리긴 했지만 원리 자체는 결국 분포와의 분포 거리를 좁히기 위해 이런 개념을 도입한 거라고 보면 된다.
6가지 생성 모델링 방식 : GAN
4.1 소개
우리나라에서 화폐를 위조하면 범죄가 된다. 범죄임에도 사람들이 위조 지폐를 만드는 이유는 돈이 되기 때문이다. 애초에 화폐를 위조하기 쉽게 만들면 선의의 피해자가 생길 수 있기 때문에 화폐를 만드는데는 위조하기 힘들게 여러 구분장치들을 마련해둔다. 그럼에도 불구하고 위조 지폐 역시 정교해지고 있다. 결국은 돈이 되기 때문에 위조 지폐와 지폐는 서로 닮아간다.
GAN은 이런 지폐와 위조지폐의 원리와 동일하다. 여기서 위조지폐는 생성자이고, 위조지폐와 지폐를 구분하는 사람이 판별자이다. 이 둘을 서로 경쟁시킴으로써 우리가 의도한 이미지를 생성하게 만드는 방식이다.
4.2 심층 합성곱
서로 비슷하게 만드는 것이 해결하려는 문제이기 때문에 이미지의 품질은 매우 높아진다는 장점이 있다. (고품질의 이미지를 따라하도록 학습시키면 모델이 만들어내는 이미지 또한 고품질이 되어간다는 의미)
4.2.1 레고 블록 데이터셋
여기서 배우는 레고 블록은 다양한 각도에서 촬영한 50가지 레고 블록 데이터의 몇가지 예시 이미지를 데이터셋으로 만들었다.
데이터셋 바로가기 ( https://www.kaggle.com/datasets/joosthazelzet/lego-brick-images )
프로그래밍 환경
1. 본인의 환경에서 "bash scripts/downloaders/download_kaggle_data.sh joosthazelzet lego-brick-images"를 입력하면 된다.
2. 캐글에서 그냥 notebook 만들어도 된다.
이전의 코드에서는 padding = "same"을 줬는데 이번에 "valid"를 주는 것이 조금 헷갈렸는데 아래 블로그에서 잘 정리해주셔서 여기를 참고하면 된다. ( https://ardino.tistory.com/40 )
간단 정리로 valid는 패딩을 미적용하는 것, full은 패딩을 (필터의 크기 -1)만큼 주는 것, Same은 입력과 출력의 크기가 같도록 패딩을 설정해주는 것이다.
훈련 전체 메커니즘
사실 우리가 밑에서 작성할 판별자와 생성자 코드는 거의 다른 모델(생성 모델)들과 크게 다를바가 없지만 훈련과정이 약간 다르다.
GAN의 핵심은 판별자에게 있는데 판별자는 "진짜 샘플"과 "생성자의 출력"을 합쳐서 이를 지도 학습의 문제로 다룹니다.
진짜 레이블이 1이고 생성한 출력의 레이블이 0로 해서 손실 함수로 이진 크로스 엔트로피를 사용한다.
이 때 한번의 학습과정에서 판별자, 생성자 하나씩만 학습(가중치 업데이트)시켜야한다. 생성자를 훈련할 때 판별자를 훈련시켜버리면 판별자가 생성자를 잘 판별하도록 학습시키는게 아니라 그냥 맞춰주도록 조정될 수도 있기 때문입니다.
4.2.2 판별자

위의 원칙에 따라 판별자는 생성한 이미지와 기존 레고 이미지가 섞인 데이터셋을 입력값으로 받아서 기존 레고이미지에 속하는지에 대해서 0~1사이의 예측값을 내뱉는다. 그 이후에 실제 같은 이미지인지 비교해서 그 차이만큼 역전파를 시킨다.
4.2.3 생성자
생성 AI의 목표는 실제(여기서는 훈련데이터)와 유사한 이미지들을 만들어내는 것이다. 따라서 생성자의 역할이 중요한데 여기서는 위에서 판별자가 평가한 로스를 줄이도록 학습시킨다. (이 때 레이블은 다 1로 표현한다.)
판별자와 다른 점은 생성자는 loss를 줄이기 위해서 이미지 생성에 대한 가중치를 학습하는 반면에 판별자는 레고 이미지가 맞다 아니다를 판별하는 역할을 한다.

4.2.4 ~ 4.2.5 DCGAN 훈련과 팁
실제 하이퍼 파라미터를 조정하는 코드와 위의 신경망 구조에 대한 코드는 아래 캐글 노트북에서 볼 수 있습니다.
https://github.com/Perelman-0/Generative_Deep_Learning_2nd_Edition
Tip
GAN을 훈련할 때 훈련 레이블에 랜덤한 잡음을 소량 추가하면 유용합니다. 이렇게 하면 훈련 과정의 안정성이 개선되고 이미지를 선명하게 생성할 수 있습니다. 이를 레이블 평활화라고 하며 판별자를 길들이는 역할을 합니다. 판별자가 풀어야할 과제가 더 어려워지므로 생성자를 과도하게 압도하지 못합니다.

훈련시킬 때의 핵심은 사실 다른 신경망과 다르게 판별자와 생성자가 우위를 차지하려고 끊임없이 경쟁하기 때문에 DCGAN 훈련 과정이 불안정해질 수 있다는 점입니다. 즉 한쪽이 우세해지면 나머지는 사실 제대로 학습되기가 어려운 점이 있습니다. 이때 판별자와 생성자 중에, 생성자를 학습하는 것이 더 어렵습니다. 예를들어, 판별자는 real/fake 만 구분하면 되지만, 생성자는 몇백 픽셀의 이미지를 직접 생성해야하기 때문입니다. 즉 판별자 D가 생성자 G보다 학습이 쉽다는 것입니다.
1. 판별자가 생성자보다 훨씬 뛰어난 경우
판별자가 너무 학습을 잘해서 성능이 뛰어나지게 되는 경우에는 생성자가 아무리 열심히 컨텐츠를 유사하게 잘 만들어도 판별자가 잘 구분하게 되고 그에 따라 Vanishing Gradient가 발생하게 된다.
처음에는 잘 구분하면 Loss 값이 커지는데 왜 Vanishing Gradient가 발생하지? 생각했는데 너무 잘 구분하게 되면 label값으로 0을 내뱉게 되어서 gradient 곱할때마다 0에 가까운 숫자가 곱해지면서 줄어든다는 의미를 이해하는데 꽤 시간이 오래 걸렸다.
아래의 작업을 통해서 성능을 조금 낮추는 작업이 필요하다.
- 판별자에 있는 Dropout 층의 매개변수값을 올려서 네트워크를 통해 흐르는 정보의 양을 줄인다.
- 판별자의 학습률을 줄인다.
- CNN 필터수 줄여보기
- 레이블에 잡음 추가
- 일부 이미지의 레이블을 무작위로 뒤집는다.
2. 생성자가 판별자보다 훨씬 뛰어난 경우
판별자가 별로 안 뛰어나면 거의 동일한 이미지 몇개만 가지고 계속 판별자를 속이는 방법을 찾는다. 이를 mode collapse라고 한다.
예를 들어 판별자가 어떠한 경우에라도 "1"이라고 구분하는 이미지 X가 있다고 하자. 그렇다면 생성자는 모든 random noise를 X로 변환하는 방법으로 최적화해나갈 수 있다.
이렇게 될 경우에는 loss back propagation이 일어나지 않아서 이후의 상태에서 벗어날 수 없게 된다.
3. 유용하지 않은 손실
생성자의 경우에는 판별자의 판단을 기준으로 loss가 만들어지는데 판별자(discriminator) 자체가 지속적으로 변하기 때문에 훈련 시점간의 비교를 하기가 어렵다.
따라서 이미지 품질이 향상됨에도 생성자의 손실함수가 증가되는 경우가 있어서 측정이 어려운 문제가 있다. 즉 생성자와 판별자의 성능에 대한 연관성 부족이 훈련과정을 모니터링하기 어렵게 만든다는 점이 있다.
4. 하이퍼 파라미터
두개의 모델을 동시에 학습시켜야하다보니 하이퍼 파라미터가 굉장히 많다. 심지어 노이즈 자체도 개발하는 입장에서 다르게 설계할 수도 있습니다.
전체 구조, 배치 정규화, 드롭아웃, 학습률, 활성화 층, 합성곱 필터, 커널 크기, 스트라이드, 배치 크기, 잠재공간 크기 등 많은데 각각의 작은 변화에도 매우 민감해서 계획적인 시행착오를 거쳐 잘 맞는 파라미터 조합을 찾는 경우가 많다.
앞에 나온 이슈들을 해결한 모델들을 다음 장에서 설명한다.
4.3 와서스테인 GAN - 그래디언트 페널티
참고 링크
- https://ahjeong.tistory.com/7
- https://www.slideshare.net/ssuser7e10e4/wasserstein-gan-
1. 해결하려는 문제
- 판별자, 생성자의 성능에 대한 연관성 문제 -> 손실함수를 재정의
- 최적화 과정의 안정성 향상
2. 와서스테인 손실함수
앞에서 우리는 생성한 이미지의 분포와 실제 테스트 이미지의 분포 차이를 BCE Loss를 통해 측정했다. 이는 판별자와 생성자 성능이 align되지 않은 문제를 일으키는데 이를 해결하기 위해서 분포의 차이(거리)를 다르게 정의한 방식이 와서스테인 손실함수이다.
기존의 판별자에서는 Yi를 0과 1로 판단했다면 와서스테인은 -1과 1을 사용한다. 또한 판별자의 마지막 층에서 시그모이드 함수를 제거해서 예측 pi가 0~1로 국한되었던 것을 풀어 어떤 범위의 숫자도 될 수 있도록 만듭니다. (출력값이 0으로 할 경우 발생하는 vanishing gradient 문제를 해결)
와서스테인 손실함수는 다음과 같이 정의합니다. (여기서는 Discriminator 대신에 Critic이라고 표현합니다.) 이에 대한 설명은 위의 참고링크 2번째를 살펴보시면 이해하시기 편할 것 같습니다.

실제 이를 목적함수 식으로 표현해보면 아래와 같이 나타낼 수 있고, WGAN은 진짜 이미지와 생성된 이미지에 대한 예측 사이의 차이를 최대화한다고 볼 수 있다.
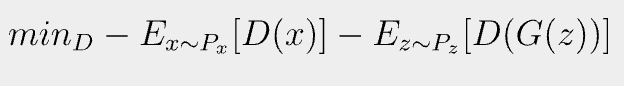
생성자에 대한 손실함수는 아래와 같이 쓰며 비평자로부터 가능한 한 높은 점수를 받는 이미지를 생성하려고 하는 것이다.

3. 립시츠 제약
책에서는 아래와 같이 립시츠 제약이 필요하다고 얘기했지만 이와 더불어 실제로 와서스테인 거리를 측정하는데 있어서 1-립시츠 제약을 충족해야 제대로 계산할 수 있다. 시그모이드 함수를 제거했기 때문에 Critic은 무한한 수의 범위를 가지는데 신경망에서 매우 큰 숫자는 역전파 학습 과정에서 overflow를 만들 수 있어서 큰 숫자가 나오지 않도록 조정이 필요하다. (이에 대한 자세한 내용은 이 링크에 잘 정리되어 있다.)
립시츠 제약을 보장하기 위해서 크게 2가지 방법이 있다.
1. 가중치 클리핑 : 가중치의 값을 일정 범위 내로 제한하는 방식
2. 그래디언트 페널티 : 그래디언트의 크기를 제한하여 조건을 충족시키는 방식 (그래디언트 노름이 1에서 벗어날 경우 모델에 패널티를 주는 방식)

와서스테인 방식으로 인해서 생성자 업데이트 사이에 비평자를 여러번 훈련하여 수렴에 가까워지도록 해도 되고, 일반적으로는 생성자 1번에 Critic을 3~5번 업데이트한다.
위에서 보다시피 모든 구간에서 그래디언트 페널티를 하기 보다는 무작위로 Interpolated한 이미지에 대해서 그래디언트 패널티를 계산한 후에 손실함수에 더해주는 방식이다.(이걸 이해하는데 오래걸렸는데 의도 자체는 가짜 이미지이든 진짜 이미지이든 간에 둘다 학습시키면서도 다 페널티를 계산하는 번거로움을 해결할 수 있다는 점에서 좋습니다.)
주의사항
critic에서는 배치 정규화를 사용하면 안되는데 이는 같은 배치 안의 이미지 사이에 상관관계를 만들기 때문에 그래디언트 페널티 손실의 효과가 떨어진다는 점이다.

4. 조건부 GAN(Conditional GAN)
이전 GAN 모델은 단순히 생성하려는 이미지만 학습 데이터로 사용했다면 조건부는 말그대로 특정 속성을 부여하는 개념이다. 예를 들면 남자 여자인지에 대해서 추가적인 속성을 같이 학습시키는 것이다.

핵심은 아래와 같이 단순히 저런 속성을 넣은 것만으로도 GAN이 이 속성을 잘 학습한다는 점이다.

'Machine Learning > 유튜브, 책, 아티클 정리' 카테고리의 다른 글
| 만들면서 배우는 생성 AI 정리 6장 - Normalizing Flow 모델 (1) | 2023.12.08 |
|---|---|
| 만들면서 배우는 생성 AI 정리 5장 - Autoregressive 모델 (0) | 2023.12.04 |
| 만들면서 배우는 생성 AI 정리 3장 - VAE 모델 (0) | 2023.10.01 |
| 만들면서 배우는 생성 AI 정리 1장 (0) | 2023.09.28 |
| Machine Learning Yearning Book 정리 (0) | 2023.09.15 |



