앞서 VAE와 GAN은 생성하려고 하는 분포를 학습하기 위해 샘플링하기 쉬운 분포를 가지는 새로운 변수를 도입해서 학습시키는 방법이었다면 autoregressive model은 생성 모델링 문제를 순차적 과정(이전 값을 바탕으로 예측)으로 정의해서 해결하는 방식입니다.
LSTM Network
- RNN
RNN(Recurrent Neural Network)의 일종으로, 다른 신경망과 다르게 순차데이터를 처리하는 순환 층이 있다는 점입니다. 아래 그림을 통해 확인할 수 있는데 RNN이 해결하려는 문제 자체가 "문장"과 같이 앞의 context(문장의 경우 앞의 단어)를 이해하는 것이 중요하기 때문입니다. (한국말처럼 앞에 어떤 단어가 붙냐에 따라서 의미가 완전히 달라지기 때문에 이런 순차적인 컨텍스트를 같이 학습시키는 접근)

우측의 그림이 RNN구조인데 이렇게 항상 y(출력값)가 x가 처음들어오자마자 출력되는 것은 아니고 해결하려는 문제에 따라 다르게 나타난다.
- one-to-one : 한개 입력받고 한개 출력하는 구조로 사실 이건 일반적인 neural network와 동일하다.
- many-to-one : 여러개의 입력(x)를 받고 한개의 출력을 내는 형태로 sentiment classification를 예시로 들 수 있다.
- many-to-many : 여러개의 입력과 여러개의 출력을 내는 형태인데 입력 문장을 모두 읽고 나서 출력을 하는 형태(Machine translation)와 매시점마다 입력이 들어오고 입력이 주어질 떄마다 출력을 내보내는 형태(VIdeo classification of frame level)가 있다.
이 때 h_t에 대한 가중치는 t에 관계없이 항상 동일한 가중치를 사용하는데, 초기 값에 대한 back propagation은 동일한 w_hh에 대해 n번 곱해지다보니 Vanishing Gradient가 발생한다.(등비수열에서 1보다 작은 값을 많이 곱할수록 0에 수렴) 결국 초기 목적인 x1의 맥락을 학습하지 못하는 문제가 발생한다.
- LSTM
RNN은 cycle이 길어질수록, 앞단의 정보를 기억하기가 어렵다는 문제가 있다. 이를 Longterm Dependency Problem이라고 하는데 LSTM은 이걸 해결하기 위해 Cell State를 추가했다.

이 구조 자체를 보고 이해하기 어려운데, 아래와 같이 정리해보았다.
문제 : RNN의 Hidden state는 순차적인 정보를 잘 관리하지만 노드가 길어질수록 앞단의 정보를 기억하기 어렵다.
해결책 : 장기 기억 관리 를 위해 Cell_state는 이전 정보(Hidden_state) 중 무엇을 기억하지 않고, 기억할지를 관리하게 한다.
Cell_state의 동작은 크게 3가지 작은 신경망으로 이루어져있음
1. Forget gate : 이전 정보 중 삭제할 정보를 찾는 gate
- 삭제에 대한 기준은 현재 정보와 비교해야한다.
- 예를 들어, 문장에서 주어가 바뀌었으면 Cell state에서는 주어에 대한 정보는 삭제하는 형태
- 활성화 함수로 시그모이드를 써서, 0으로 삭제할 정보를 없애버린다.

2. input gate : 어떤 값을 다음 Cell state에 기억할 정보로 넘길지를 정하는 gate
- 이전 C_t-1에서 가져올 값에 x_t, h_t-1에서 얼마만큼 업데이트 값을 가져갈지를 조합해서 업데이트한다.

3. output gate (hidden state와 동일한데, 아웃풋인 경우에는 Output gate라고 표시)

RNN과 동일하게 Hidden state이며, 현재의 장기기억(C_t)과 현재 input 정보(h_t-1, x_t)에 가중치를 곱해서 구한다.
이미 Tensorflow나 pytorch에서 내장된 함수가 있어서 내장함수 코드는 여기서 볼 수 있다.
https://github.com/pytorch/pytorch/blob/main/benchmarks/fastrnns/custom_lstms.py
- GRU
- LSTM과 유사하지만 크게 두 가지 다른 점이 있습니다.
- Cell state없이 Hidden state가 장기, 단기 기억을 Control하는 형태
- input gate와 forget gate의 역할을 Reset gate로 한번에 처리한다.
- LSTM과 유사하지만 크게 두 가지 다른 점이 있습니다.

1. reset gate : 이전 정보 중에 어떤 정보를 가져올지(reset) 정하는 gate
- 과거 정보(hidden state) 중에 Reset할 것을 정하기 위해서는 현재 정보와 비교해야하기 때문에 input으로 h_t가 들어가고 reset_gate에서 나오는 값은 일종의 Reset_ratio이기 때문에 이를 h_(t-1)과 곱한다.
- 이후에 현재 정보와 과거 정보 중에 reset할 정보를 합쳐서 tanh(-1 ~ 1)를 activation function으로 써서, hidden state에 업데이트할 정보를 전달한다.

2. 전체 Hidden state 동작
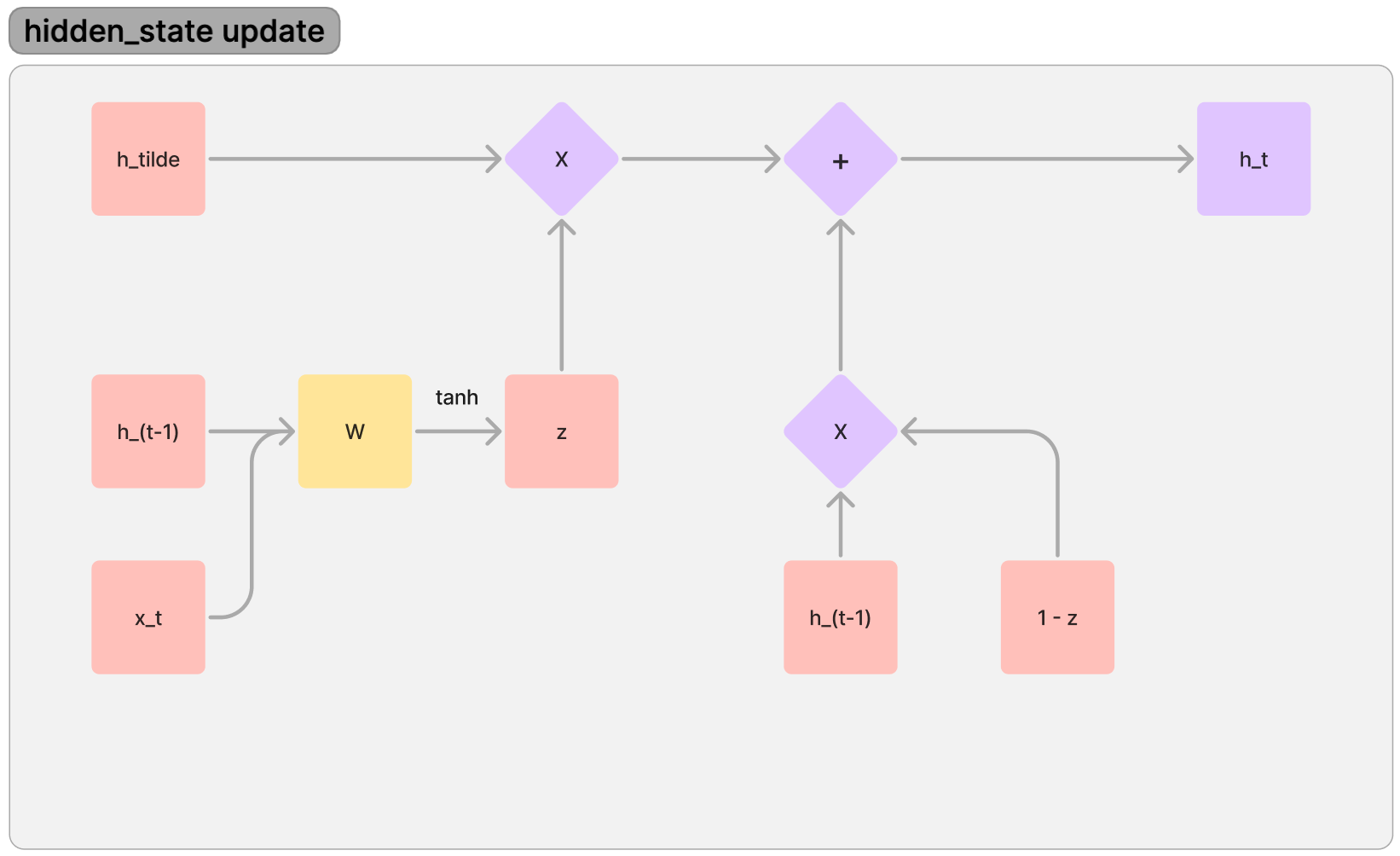
- 전체적으로 이전 정보와 현재 시점에 들어온 정보를 조합해서 다음 Hidden_state로 넘기는 형태이다.
- 여기서 z가 ratio인데, 이 때 h_(t-1)과 x_t를 고려해서 얼마만큼 h_tilde에 기여할지도 신경망으로 추론하게 한다.
- Pixel CNN
이미지 생성을 Recurrent로 재정의한 것으로 이전 픽셀을 기반으로 다음 픽셀의 가능성을 예측하는 모델.
일반적으로 CNN 자체는 Convolution Filter로 나온 값들에 대한 순서를 저장하지는 않지만 pixel CNN에서는 이를 autoregressive 형태로 적용한 것이 핵심.
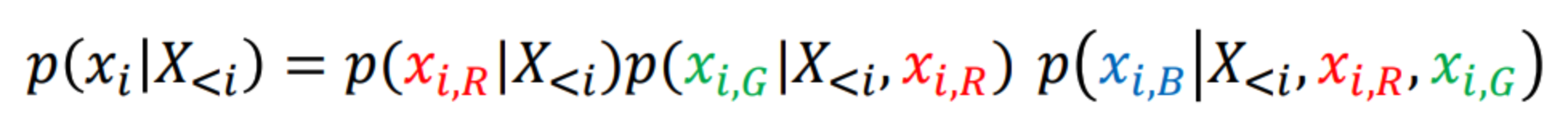
1. 개념

일반적인 CNN에 순서를 기억하게 하기 위해서는 아래 방법을 적용합니다.
- masked convolution layer
- 이전 픽셀만을 기준으로 현재 픽셀을 생성하는 모델이지만 우리의 학습 데이터는 모두 완성된 이미지밖에 없다. 이를 어떻게 처리할 수 있을까?
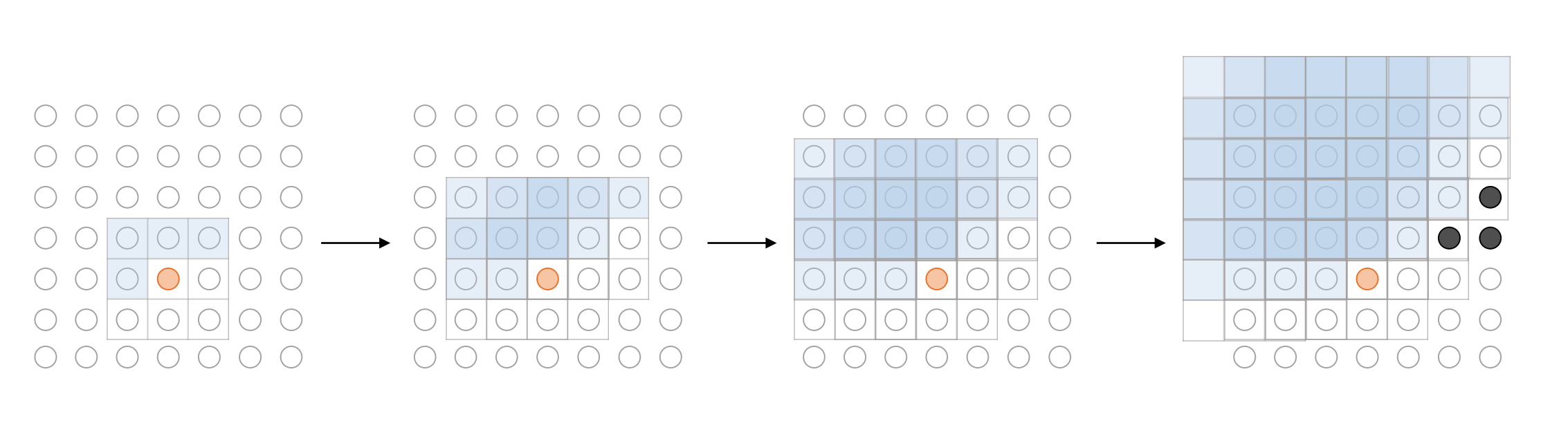
- 위의 그림 예시를 들어보자
- 현재 모델이 파란색 픽셀(13)을 예측하기 위해서는 앞서 12개의 빨간색으로 표시된 픽셀만 보고 13을 예측하도록 훈련시켜야 하고 예측 대상인 파란색을 비롯해 회색으로 표현된 픽셀은 몰라야한다.
- 이를 위해 파란색 + 회색으로 된 곳에 0을 넣고 빨간색은 1로 넣어서 원래 이미지에 곱해주며 이것을 masked convolution layer라고 한다.
- PixelCNN은 2개의 층으로 이루어져 있어서 처음에는 파란색, 회색 모두 0이지만, 이후에 층에서는 파란색의 경우 1로 채워준다.(그 이유는 이미 첫번째 층에서 현재 픽셀에 대해 계산을 완료했기 때문에.)
2. loss_function
- 모델의 output : 0 ~ 255개 class 각각에 대한 Softmax값으로 처리(확률화)
- loss_function : CrossEntropy(다중 분류문제)로 적용하는데 one-hot vector가 아니기 때문에 'sparse_categorical_crossentropy'를 사용한다.
-
- 개별 픽셀 손실 계산: 모델이 각 픽셀에 대해 클래스 확률을 예측할 때, sparse_categorical_crossentropy 손실 함수는 각 픽셀의 실제 값과 모델이 예측한 확률 분포 사이의 크로스 엔트로피를 계산.
- 전체 이미지 손실의 합산: 각 픽셀에 대한 손실 값은 자동으로 합산되어 전체 이미지에 대한 손실 값을 제공합니다. 한 이미지 내의 모든 픽셀에 대한 손실들의 합.
- 평균 손실 계산: 트레이닝 배치 내의 모든 이미지에 대한 손실 값들은 평균을 내어 배치 손실을 계산합니다. 이는 model.fit 함수에서 자동으로 이루어집니다. 배치 내의 각 이미지에 대한 평균 손실을 계산하여, 이를 사용하여 모델의 가중치를 업데이트
-
3. 단점
- CNN도 느린데, autoregressive 한 성격 때문에 병렬 처리도 어렵고 픽셀이 커지면 커질수록 연산량도 매우 많아짐.
- 모든 픽셀의 정보를 처리하고 유지해야하기 때문에 많은 메모리가 필요합니다.
- 가장자리로 갈수록 학습을 잘 하지 못하는 문제가 존재.
4. 개선 버전
전체적인 방향은 연산에 필요한 파라미터를 줄이는 형태로 진행
- Softmax -> 혼합분포로 변경
- 학습해야하는 parameter 수 줄이기
- 연속된 픽셀들에 대해서 softmax는 class기준이어서 연속성 고려 X -> 분포를 활용하면 연속성 고려 가능
- color 채널을 하나하나 다 뽑기보다는 joint distribution으로 산출하도록 변경
- Dropout
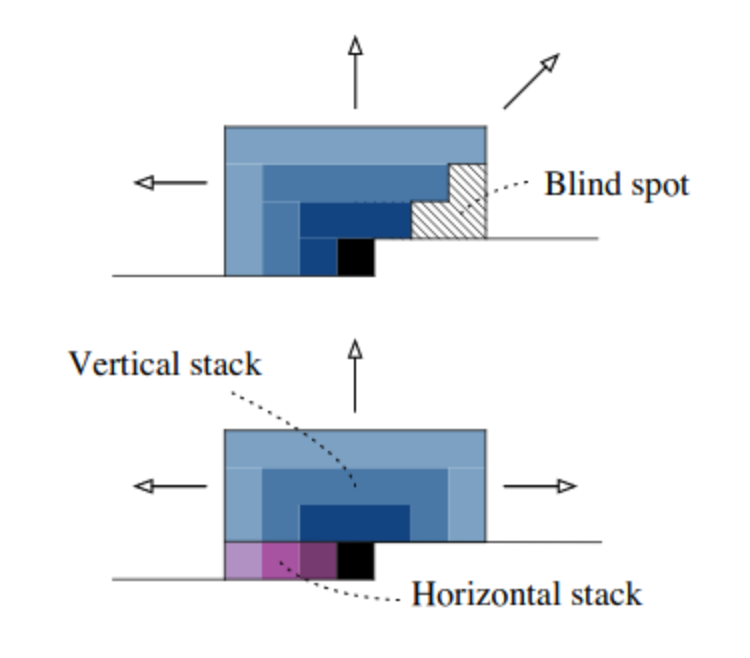
- Vertical & Horizontal Stack을 통해서 Blind Spot 제거
참고 자료
- http://dmqm.korea.ac.kr/activity/seminar/263
- https://arxiv.org/abs/1601.06759v3
- https://velog.io/@pabiya/PIXELCNN-IMPROVING-THE-PIXELCNN-WITHDISCRETIZED-LOGISTIC-MIXTURE-LIKELIHOOD-ANDOTHER-MODIFICATIONS
'Machine Learning > 유튜브, 책, 아티클 정리' 카테고리의 다른 글
| 만들면서 배우는 생성 AI 7장 : Energy Based 모델 (1) | 2023.12.10 |
|---|---|
| 만들면서 배우는 생성 AI 정리 6장 - Normalizing Flow 모델 (1) | 2023.12.08 |
| 만들면서 배우는 생성 AI 정리 4장 - GAN 모델 (1) | 2023.11.21 |
| 만들면서 배우는 생성 AI 정리 3장 - VAE 모델 (0) | 2023.10.01 |
| 만들면서 배우는 생성 AI 정리 1장 (0) | 2023.09.28 |



